
Surprise surprise
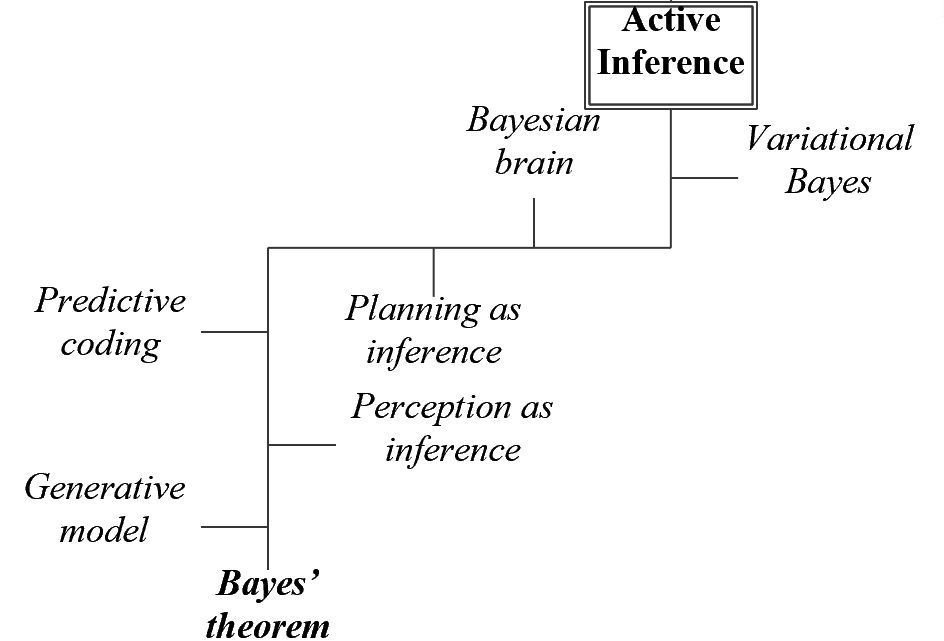
Na alle Bayesiaanse omzwervingen ben ik weer terug op het pad, althans op de door Karl Friston cs uitgestippelde route, de low road, naar active inference. In het schema hieronder zie je de stopplaatsen die ik onderweg wil aandoen om te begrijpen waar het om gaat.
Ik ben op dit pad omdat ik geïnteresseerd ben in het idee van Friston dat je beter een ‘ecosysteem van samenwerkende natuurlijke en kunstmatige intelligent agents‘ zou kunnen ontwerpen dan door te ontwikkelen met steeds extremere, monolithische, systemen zoals LLM.
Zo’n ecosysteem is een verzameling generatieve modellen die gedrag, cognitieve en neurale processen beschrijven. Ik zie het als een theoretisch kader om te verklaren hoe biologische systemen functioneren en interacteren met hun omgeving en daarin overleven. De kern van active inference systemen is dat ze zichzelf continu een intern beeld van de wereld vormen en dat door perceptie en actie zodanig bijstellen dat de discrepantie tussen de op dat wereldbeeld gebaseerde voorspelde en werkelijke waarnemingen wordt geminimaliseerd. Begrijpen van de wereld noemden we dat in eerdere berichten.
Mijn plan was om het boek Active Inference te volgen, maar al snel kwam ik er achter dat met mijn vooralsnog gebrekkige voorkennis het pad niet zo geëffend is als ik had gehoopt. Deze weg gaat over gravel, met onverwacht scherpe steentjes en soms bochten die door het opgewerkte stof niet overzichtelijk zijn. Een echte Strade Bianche zou een liefhebber van wielerklassiekers zeggen.

De tocht begint lieflijk genoeg. De hobbel van de stelling van Bayes hebben we al genomen.
De eerste stopplaatsen, Generative model en Perception as inference hebben een ruime eigen historie, die begint bij Helmholtz.
Helmholtz publiceert in 1867 zijn Handbuch der physiologischen Optik, met daarin het volgende citaat:
“Die Bildung der Gesichtseindrücke geschieht hauptsächlich durch unbewusste Urteile, deren Resultate niemals auf die Stufe der bewussten Urteile erhoben werden können und daher der reinigenden und prüfenden Arbeit des bewussten Denkens entbehren.“
“Perception as unconscious inference” heet dat bij Friston.
Perceptie
Helmholtz geeft als voorbeeld de zon die in onze waarneming door onbewuste inferentie om de aarde lijkt te draaien en iedere avond achter de horizon zakt, terwijl we weten dat de zon stilstaat en de aarde draait.
Een andersoortig voorbeeld, niet in deze vorm bij Helmholtz: Stel dat je op een avond die zich ervoor leent naar de maan kijkt, de maan waarneemt. Ergens in je hersenen vormt zich nu een beeld van de maan dat je later kunt inzetten in het voorspellen van wat je ziet.
Als je een vinger voor je ogen heen en weer beweegt, zodat er telkens een stukje maan bedekt is, vorm je je niet steeds een nieuw totaalbeeld, maar combineer je de snel veranderende positie van je vinger en een stabiel ‘intern’ beeld van de maan.
De concepten van Helmholtz worden in de anderhalve eeuw na publicatie uitgewerkt tot het idee van het brein als ‘voorspellende machine’, een statistisch orgaan dat de externe toestanden van de wereld afleidt en voorspelt. Kort samengevat is dat de hypothese van het Bayesiaanse brein, die ik later apart wil gaan bestuderen.
Generatief model
Om voorspellingen te kunnen doen over wat je aan observaties kan verwachten is een generatief model nodig, ook wel forward model genoemd, ontleend aan de statistische theorie. Het gaat om de joint probability, de gecombineerde waarschijnlijkheid  van observaties
van observaties  en de verborgen toestanden (states)
en de verborgen toestanden (states)  van de wereld. Die laatste categorie betreft relevante factoren die je niet direct kunt waarnemen.
van de wereld. Die laatste categorie betreft relevante factoren die je niet direct kunt waarnemen.
De gecombineerde verwachting heeft twee componenten:
- De prior
 , je belief, dat wat je verwacht over de verborgen toestanden van de wereld.
, je belief, dat wat je verwacht over de verborgen toestanden van de wereld. - De likelihood
 , de waarschijnlijkheid van wat ik waarneem, gegeven mijn belief over de omstandigheid
, de waarschijnlijkheid van wat ik waarneem, gegeven mijn belief over de omstandigheid  .
.
 , de waarschijnlijkheid van wat ik waarneem, gegeven mijn belief over de omstandigheid
, de waarschijnlijkheid van wat ik waarneem, gegeven mijn belief over de omstandigheid Terminologie: het generatieve model bestaat uit de prior en de likelihood samen.
Met de formule van Bayes kunnen we deze twee componenten combineren.
![\[P(s|o)=\frac{P(o|s)*P(s)}{P(o)}\]](https://usercontent.one/wp/corsai.ronde3.nl/wp-content/ql-cache/quicklatex.com-300e4680136d57236e7fb197da1e77ad_l3.png?media=1727769617 "Rendered by QuickLaTeX.com")
Daarmee wordt de prior  bijgewerkt, geüpdatet, tot een posterior
bijgewerkt, geüpdatet, tot een posterior  . Dat is mijn (hernieuwde) begrip van de (verborgen) wereld (), gegeven mijn observaties ().
. Dat is mijn (hernieuwde) begrip van de (verborgen) wereld (), gegeven mijn observaties ().
 tenslotte wordt de marginal likelihood genoemd, ook wel model evidence. De tweede benaming is inzichtelijker omdat het iets zegt over de waarschijnlijkheid dat de observaties daadwerkelijk optreden gegeven mijn belief, mijn geheel aan model parameters. Het zegt iets over de gegrondheid van mijn belief: hoe goed past mijn model nog bij de waargenomen data? In het eerder besproken voorbeeld van de medische diagnose test betrof de model evidence alle positieve testen, d.i. de gecombineerde waarschijnlijkheid van de correct positief geteste gevallen plus de false positives.
tenslotte wordt de marginal likelihood genoemd, ook wel model evidence. De tweede benaming is inzichtelijker omdat het iets zegt over de waarschijnlijkheid dat de observaties daadwerkelijk optreden gegeven mijn belief, mijn geheel aan model parameters. Het zegt iets over de gegrondheid van mijn belief: hoe goed past mijn model nog bij de waargenomen data? In het eerder besproken voorbeeld van de medische diagnose test betrof de model evidence alle positieve testen, d.i. de gecombineerde waarschijnlijkheid van de correct positief geteste gevallen plus de false positives.
Op weg naar Active Inference is het belangrijk om dit in gedachten te houden, cruciaal zelfs volgens Tom Chivers in zijn geweldige boek Everything is Predictable.
- De likelihood plaatst de waarnemingen die ik doe in het kader van mijn opvattingen, verklaart in zekere zin waarom ze zo zijn. Chivers noemt dit sampling probabilities.
- De marginal likelihood doet precies het omgekeerde: de waarnemingen zijn wat ze zijn, maar wat zeggen ze over het totaal? Had ik ze kunnen verwachten op basis van mijn opvattingen of moet ik die bijstellen? Bij Chivers zijn dit de inferential probabilities.
Voorbeeld
In het boek Active Inference wordt een wat vreemd onzinvoorbeeld gebruikt om de concepten die een rol spelen verder aan te scherpen. Ik gebruik het in parafrase hier ook, voor hetzelfde doel. Dit is het voorbeeld:
Iemand heeft een object voor zich waarvan ze het sterke vermoeden heeft dat het een appel is. Dat is haar prior hypothese over de wereld, binnen haar belief over de wereld dat ook alternatieve hypothesen omvat. In dit voorbeeld is de (enige) alternatieve hypothese dat het object een kikker is. Laten we de kansverdeling zo maken dat de waarschijnlijkheid van een appel 0,9 is en van een kikker 0,1. In deze situatie gaat haar belief dus over de twee ‘hidden states‘ (kikker of appel).
De persoon in kwestie beschikt ook over een voor de situatie relevant likelihood model waarin het zeer waarschijnlijk is dat de kikker springt en de appel niet. In dit voorbeeld zijn er twee observaties (springen of niet springen). Ook aan de springkans kennen we in dit voorbeeld waarden toe, laten we zeggen een kans op springen van 0,81 bij de kikker en 0,01 bij de appel.
Verrassing
Het appel-kikker-object springt! Nu kan de prior worden geüpdatet naar een posterior met behulp van de formule van Bayes.
Even rekenen. We hebben het over twee ‘states’ : appel of kikker, en twee observaties , sprong of geen sprong.
Prior:  en
en 
Likelihood:  en
en 
De formule van Bayes in deze termen:
![\[P(appel|sprong)=\frac{P(sprong|appel)*P(appel)}{P(sprong)}=\frac{0,01*0,9}{0,09}=0,1\]](https://usercontent.one/wp/corsai.ronde3.nl/wp-content/ql-cache/quicklatex.com-ae18768ae692944ef0f6d2477b9d3aa5_l3.png?media=1727769617 "Rendered by QuickLaTeX.com")
De a priori verwachting van 90% dat het object een appel was, moet dus na de waargenomen sprong worden bijgesteld naar 10%.
De berekening voor de marginal likelihood is als volgt:
![\[P(sprong)= P(kikker)*P(sprong|kikker) + P(appel)*P(sprong|appel)=0,1*0,81+0,9*0,01= 0.09\]](https://usercontent.one/wp/corsai.ronde3.nl/wp-content/ql-cache/quicklatex.com-6433ddb7176b9da7f1d47bb2124c0804_l3.png?media=1727769617 "Rendered by QuickLaTeX.com")
In het boek Active Inference gaat het nu verder met de notie surprise, verrassing. Niet vreemd, want we weten al dat het een organisme er om te doen is de discrepantie tussen waarnemingen en eigen generatief model zo laag mogelijk te houden, zeg maar het surprise niveau te minimaliseren.
Wegversperring
De wiskundige definitie van verrassing was voor mij een verrassing op zichzelf: surprise is de negatieve logaritme van de marginal likelihood.
Toegepast op ons voorbeeld, in formule:  .
.
Zo kun je er nog een waarde aan toekennen ook: 
Met gebruik van de natuurlijke logaritme  wordt de eenheid van verrassing de nat genoemd, met
wordt de eenheid van verrassing de nat genoemd, met  , de logaritme met grondtal 2, zou de surprise worden uitgedrukt in bits. In dit geval
, de logaritme met grondtal 2, zou de surprise worden uitgedrukt in bits. In dit geval 
Tja, die zag ik ook niet zo snel aankomen. Surprise surprise…
Uitleg en achtergrond van deze definities zijn goed te vinden en te vertellen, maar voor nu ligt er een wegversperring op het ingeslagen pad. In volgende berichten zal ik proberen die weg te ruimen.
Mijn complimenten voor je mooie en interessante verhalen! Twee opmerkingen voor wat ze waard zijn. (1) De formule ‘surprise’ = – ln P laat mooi zien dat de verassing groot is als de kans dat de gebeurtenis zich voordoet klein is (- Ln P gaat immers naar oneindig als P naar nul gaat). (2) Het grote probleem in dit soort berekeningen is dat de marginal likelihood in complexere situaties moeilijk is te bepalen. Het is méér dan een normaliseringsfactor, nodig om de posterior tussen 0 en 1 te houden. Voor de bepaling daarvan moet je alle mogelijkheden kennen die zich kunnen voordoen. In dit grappige voorbeeld gaan we ervan uit dat alleen een kikker en een appel kan springen, met bijbehorende springkansen. In een realistische situatie zijn er veel meer objecten die kunnen springen en die betrokken moeten worden. Voor een goede voorspelling moet je ze allemaal kennen, Doordat je in realistische situaties te maken een groot aantal mogelijke hypothesen, worden berekeningen complex en moeilijk uit te voeren. Daarom hebben statistici benaderingsmethoden bedacht.
Dank voor je zinnige opmerkingen! Het op het toneel verschijnen van de logaritme geeft me de gelegenheid om een interessant zijpad in te slaan, richting informatietheorie en Claude Shannon. Hij is de eerste die het concept surprisal of zelfinformatie heeft gebruikt in zijn standaardwerk uit 1948 (!), kan ik ook gelijk verbinding maken met het begrip informatie-entropie dat snel al weer nodig is bij het vervolg over Active Inference.