
Héél grote dataverzamelingen
Taalmodellen zoals GPT-3 worden gereedgemaakt voor gebruik door ze te ‘trainen’ op grote dataverzamelingen. Ik denk al wel te begrijpen dat de onvoorstelbare omvang van het corpus waarop GPT-3 is getraind een van de kantelpunten markeert waarnaar ik op zoek ben, in de ontwikkeling van natuurlijke taalverwerking.
Vragen waar ik later op terug kom:
- hoe werkt het trainen van een taalmodel?
- is het nodig om zulke grote dataverzamelingen te gebruiken?
- wat zijn de neveneffecten van het werken met ongecensureerde en niet-gemodereerde inhoud?
De dataverzamelingen onder GPT-3
GPT-3.5 is getraind op 5 grote dataverzamelingen: Wikipedia, Common Crawl, WebText2, Books1, Books2 zoals die medio 2021 waren.
Alleen die eerste klinkt bekend. Om het corpus op te bouwen zijn alle pagina’s in alle talen van Wikipedia ‘opgeslorpt’. Ik kon geen recentere gegevens dan 2015 vinden voor de totale omvang, maar toen waren er 34 miljoen ‘artikelen’ (ik vermoed: pagina’s) in 288 verschillende talen.
Huiver nog meer bij Common Crawl. Een crawler is een computerprogramma dat geautomatiseerd informatie op het gehele internet opzoekt en op een bepaalde manier opslaat en indexeert. Alle zoekmachines gebruiken eigen crawlers om hun zoekindexen op te bouwen. Common Crawl is een non-profit organisatie “dedicated to providing a copy of the internet to internet researchers, companies and individuals at no cost for the purpose of research and analysis“. De organisatie is in 2008 met eigen crawlers (zoals CCbot) begonnen te verzamelen en te indexeren en doet dat tot op de dag van vandaag.
Om je een indruk te geven van de omvang: het crawl resultaat van mei en juni 2023 bevat 3,1 miljard ‘gevangen’ webpagina’s bij 44 miljoen hosts, inclusief 1 miljard nieuwe URL’s die niet eerder bezocht waren. Het resultaat is openbaar beschikbaar en kun je zelfs downloaden. De ongecomprimeerde opslag is 390 TiB…
Ook hier gaat het om inhoud in een groot aantal (40+) talen die op het internet aanwezig zijn.
WebText2 is een corpus van 40 GB tekst, in 8 miljoen documenten die afkomstig zijn van, of gelinkt aan, het Reddit platform van 2005 – 2020.
Books1 en Books2 zijn verzamelingen van e-books. De maker van GPT (OpenAI) is terughoudend met het geven van informatie over deze verzamelingen, mogelijk om auteursrecht issues te vermijden. Vrijwel zeker is Books1 het zg. Gutenberg corpus dat uit ruim 60.000 boeken bestaat die auteursrecht vrij zijn. Books2 bestaat mogelijk uit 11.000 nog niet gepubliceerde boeken die van internet geschraapt zijn.
Omvang
Alles bij elkaar is de verzameling content waarop GPT-3 is getraind van een nauwelijks voor te stellen omvang. De gehele (tekstuele) inhoud van alle websites op het internet zeg maar, aangevuld met inhoud van een van de grootste inhoudelijke social media platforms ter wereld en een grote bibliotheek aan boeken, waaronder alle klassieke werken.
GPT is niet het enige grote taalmodel. In de figuur zie je de ontwikkeling in de afgelopen jaren van de omvang van grote taalmodellen, op een logaritmische schaal. GPT-3 is 150x zo groot als zijn voorganger GPT-2.
Het gaat om de omvang in berekende parameters op basis van het corpus, ‘billion’ betekent hier: miljard.
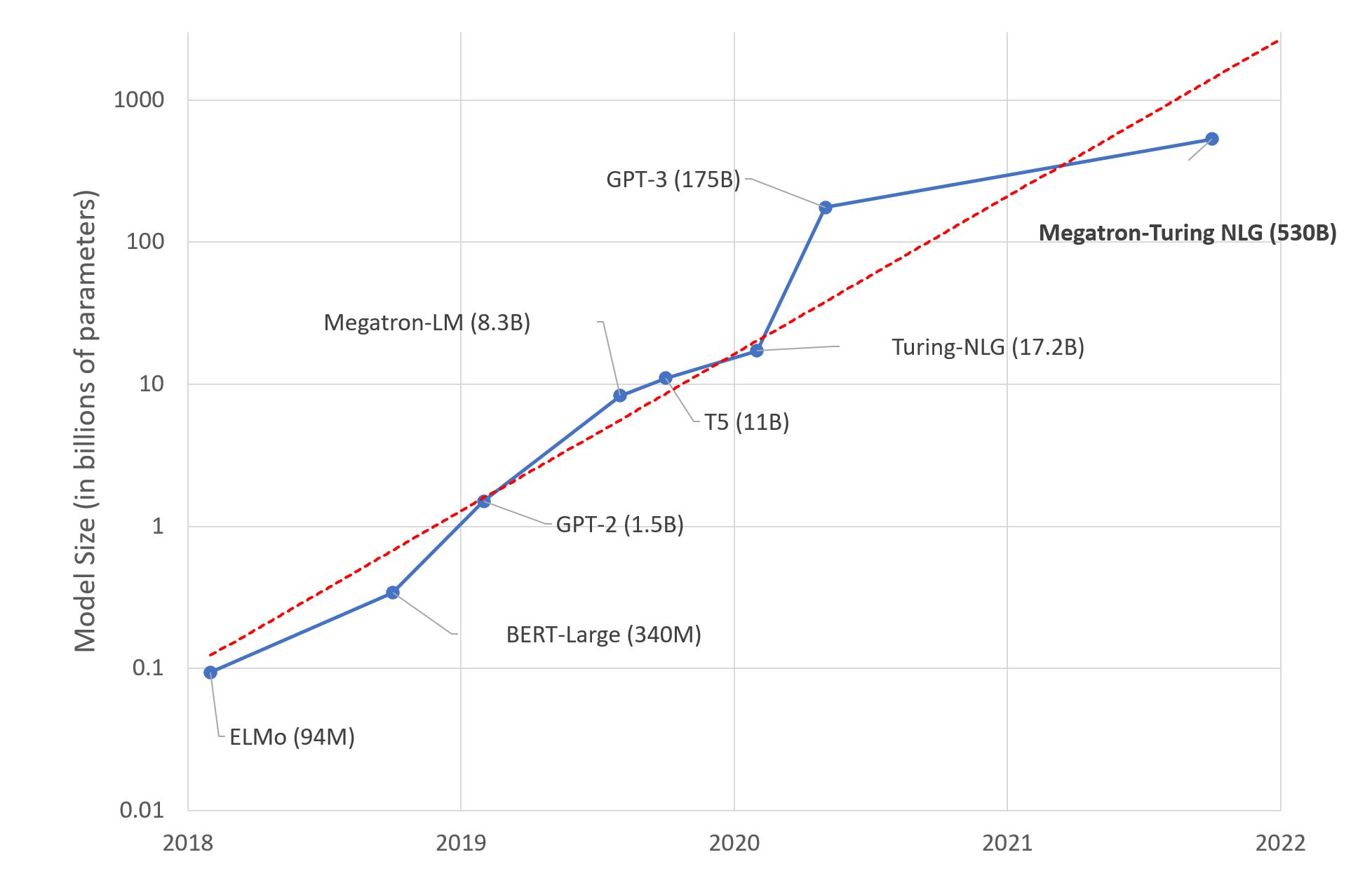
Bron: Microsoft Research Blog 11 oktober 2021.