
Ontwoorden
Computers kunnen niet zo maar werken met tekst. Woorden en zinnen moeten eerst omgezet worden in getalsmatige vormen. Die vertaling, vectorisatie, is de laatste stap in een serie voorbereidingen die de preprocessing pipeline wordt genoemd.
Tekst opschonen
Alle coderingen (html, url’s, tags e.d.) worden verwijderd. Alle tekst wordt naar kleine letters (lowercase) omgezet. Speciale tekens en nummers worden verwijderd, soms ook interpunctie. Afkortingen worden voluit geschreven. Spelfouten worden gecorrigeerd.
Tokeniseren
In deze processtap wordt de tekst gesplitst, in stukjes gehakt. Zo’n stukje wordt een token genoemd. De tokens vormen de bouwstenen voor het vervolg.
Vaak wordt er met woord tokens gewerkt (ik gebruik | om de splitsing zichtbaar te maken, het symbool zelf is geen token):
De | kat | zat | op | de | mat | .
Merk op dat de punt waarmee de zin afsluit ook als token wordt neergezet.
Sommige woorden worden in subwoorden getokeniseerd:
De | groot | ste | kat | zat | op | de | klein | ere | mat | .
Zo hoeven grootste en kleinste niet als ‘nieuwe’ woorden behandeld te worden, maar kunnen ze in verband met groot en klein gebracht worden. De tokens ste en ere zijn dan generiek voor alle woorden met een overtreffende of vergelijkende trap.
Lemmatiseren
In deze stap worden woorden tot een basisvorm teruggebracht waarop verschillende vervoegingen of samenstellingen kunnen worden herleid. Bijvoorbeeld ‘lopen’, ‘loopt’, ‘liep’, ‘gelopen’ worden alle teruggebracht tot ‘lopen’. Het zijn lexicale ‘woordenboek’ vormen zou je kunnen zeggen, bij de oudere systemen voor machinevertaling worden hiervoor daadwerkelijk lexicons gebruikt.
Dit proces wordt bij deep learning en grote taalmodellen steeds minder gebruikt. Die modellen leren zo goed en snel dat ze zelf kunnen afleiden welke vormen bij elkaar horen.
Verwijderen stopwoorden
Stopwoorden zijn in dit verband woorden die weinig bijdragen aan de betekenis van een tekst. Denk aan lidwoorden, voegwoorden, voornaamwoorden, voorzetsels, tussenwerpsels, sommige bijwoorden en bijvoeglijke naamwoorden.
Het verwijderen van stopwoorden gebeurt geautomatiseerd aan de hand van vooraf opgestelde lijsten.
Ook voor dit onderdeel geldt dat het bij de grote taalmodellen steeds minder nodig is, het model leert zelf wel welke woorden minder bijdragen aan de betekenis en kan dat zelfs beter dan met een vooraf opgestelde lijst omdat die feitelijk contextvrij is.
Woordposities bepalen
Woordvolgorde doet er toe voor de betekenis en context in een tekst zagen we eerder. Deze volgorde is bekend bij het begin van het trainen van het taalmodel en kan dus worden vastgelegd.
Er zijn verschillende methoden om die vastlegging te doen, het type neuraal netwerk dat we voor de training willen gebruiken bepaalt de keuze, als ik het goed begrijp.
Een n-gram (waarbij n = 2, 3, 4, …) is een opeenvolgende sequentie van n woord tokens. Ze worden gebruikt om woordposities vast te leggen in word embeddings. Als deze vastlegging meegenomen wordt in het trainen kunnen contextuele relaties tussen woorden beter gemodelleerd worden. Deze manier wordt gebruikt in RNN en andere non-transformer architectuur.
In de Transformer architectuur wordt een manier gebruikt die fixed positional encoding wordt genoemd. Met behulp van sinus en cosinus functies wordt informatie over de positie van woorden in de input sequentie gevoegd.
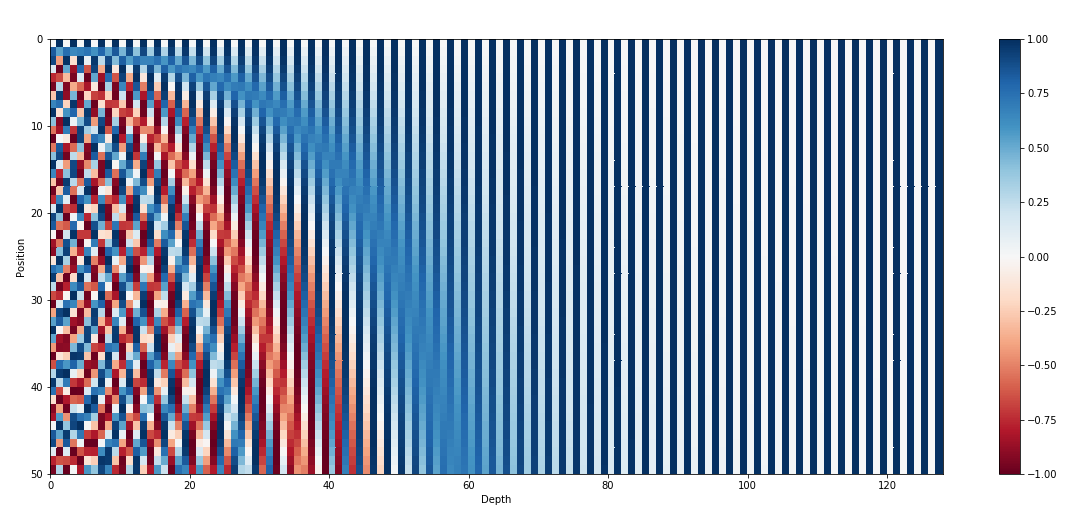
Visualisering van een matrix waarin woordposities zijn vastgelegd.
Bron: Transformer Architecture: The Positional Encoding (Amirhossein Kazemnejad, sep 2019).
Net als bij vorige stappen zou je verwachten dat ook deze codering door de grote taalmodellen zelf uitgevonden en geleerd kan worden. Er is ook mee geëxperimenteerd, maar de vaste codering vooraf bleek minstens net zo goed te werken, en is veel eenvoudiger te realiseren.
Vectoriseren
In deze processtap worden uiteindelijk de woorden, of beter gezegd de tokens, gecodeerd in getallen. Allereerst wordt het woord zelf voorzien van een eenduidige code, een index. Hoe dat coderen gebeurt ligt niet vast, er is geen universele methode. In theorie zou je het met volgnummers kunnen doen – al zal dat niet erg praktisch zijn.
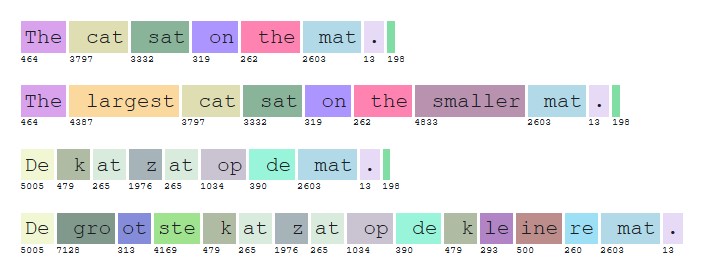
OpenAI, de makers van ChatGPT, gebruiken een manier die voor hun eigen bedrijf consistent is. Voor GPT3 is die openbaar, en zelfs als Python programmabibliotheek te downloaden voor wie zelf aan de slag wil.
En er zijn online tools waarmee je kunt ‘tokenizen’. Het plaatje is een voorbeeld. Je ziet wel dat deze token toekenning van oorsprong Engelstalig is – ‘cat’ is een eigen token, terwijl ‘kat’ gesplitst wordt in ‘k’ en het in Engels bestaande woord ‘at’. In de praktijk maakt het niet veel uit.
Hier eindigt de preprocessing pipeline en kan het model ‘in werking’ gaan.
In het deep learning proces dat dan volgt wordt per token een groot aantal features, eigenschappen, opgeslagen als een rij getallen – een vector. Dat verklaart het woord vectoriseren. Vaak kom je het begrip ‘word embedding‘ tegen, volgens mij een synoniem.
De inhoud van de vectoren kan wijzigen, afhankelijk van de uitkomsten van het leerproces.