
Omzettingsmodel
Thuis zorg ik vaak voor de koffie, maar om nu te zeggen Ik ben barista gaat wat ver. Als ik nou de ene week blogs zou schrijven en de andere week alleen maar voor koffie zou zorgen, dan zou Van de week ben ik barista kunnen kloppen.
En als ik een carrière bij Starbucks nastreef kan ik misschien ooit met trots zeggen Ik ben barista van de week.
Andere woorden in de buurt van een woord in een tekst bepalen mede de betekenis van dat woord. Bovendien heeft de woordvolgorde invloed op betekenis van woorden, in relatie met hun plaats in een zin. Voor machinevertalingen zijn dat grote uitdagingen.
Ik ben barista --> I am a barista Van de week ben ik barista --> This week I am a barista Ik ben barista van de week --> I am barista of the week
De vertalingen zijn gemaakt met het programma DeepL Translator.
In een woord voor woord vertaling zou het met de lidwoorden misschien al niet goed gaan. De toevoeging ‘van de week’ in de tweede en derde zin geeft andere semantische ladingen, en dus vertalingen. De volgorde doet er toe, al worden dezelfde woorden gebruikt.
Machinevertalingen vinden plaats in een encoder-decoder systeem. De invoersequentie kan duidelijk niet woord voor woord worden afgehandeld. Bij elk woord in de zin moet het systeem weten welke woorden er eerder kwamen, en liefst een beetje vooruit kijken naar woorden die nog gaan komen om een adequate vertaling te kunnen geven. Ook taalmodellen voorspellen de meest waarschijnlijke uitvoer, op basis van de op de prompt gebaseerde context en de woorden die er al staan.
Jargon. Het gaat hier om sequence transduction models, omzettingsmodellen.
De computers waarop deze modellen draaien voeren sequence-to-sequence taken uit. Ze lijken in staat in vloeiende natuurlijke taal te reageren op invoer door de gebruiker, de prompt. In werkelijkheid vindt de keuze voor een vervolg in de reactie woord voor woord plaats.
Een manier om om te gaan met het volgorde- en contextprobleem is het inzetten van neurale netwerken met voldoende hidden nodes om gegevens over de woorden in de tekst vast te houden totdat de gehele sequentie aan bod is geweest. Daarbij moet steeds worden teruggekeken, dit zijn zogeheten Recurrent Neural Networks (RNN).
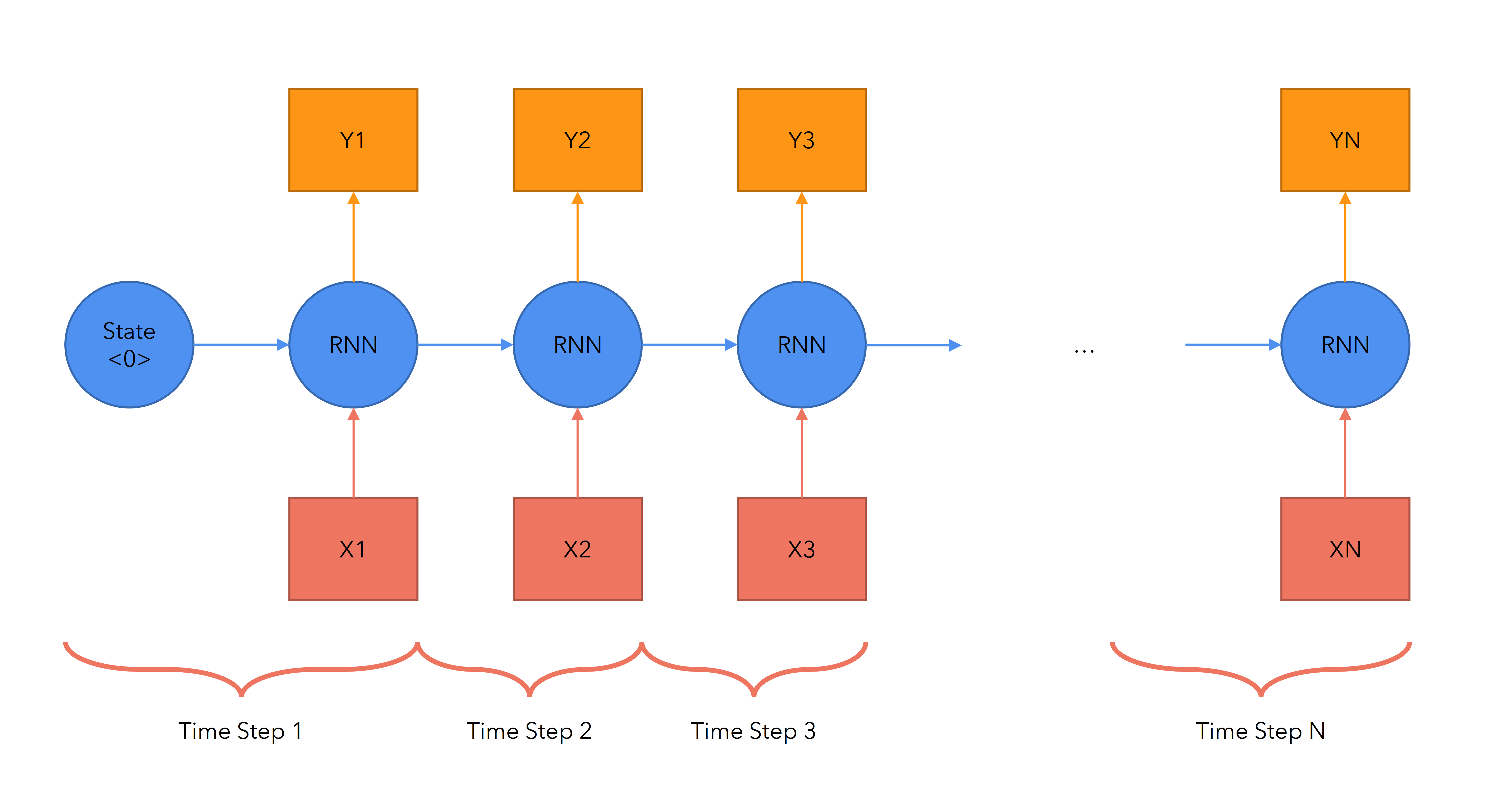
Bij grote tekstomvang werken RNN niet meer goed. Het aantal mogelijkheden dat in de lucht gehouden moet worden neemt exponentieel toe met de omvang van de tekst. En als twee woorden, die elkaar in betekenis beïnvloeden, ver uit elkaar staan is het RNN soms het eerste woord ‘vergeten’ als het tweede woord aan de beurt is: er is geen (geheugen)ruimte om beide woorden te blijven bedienen.
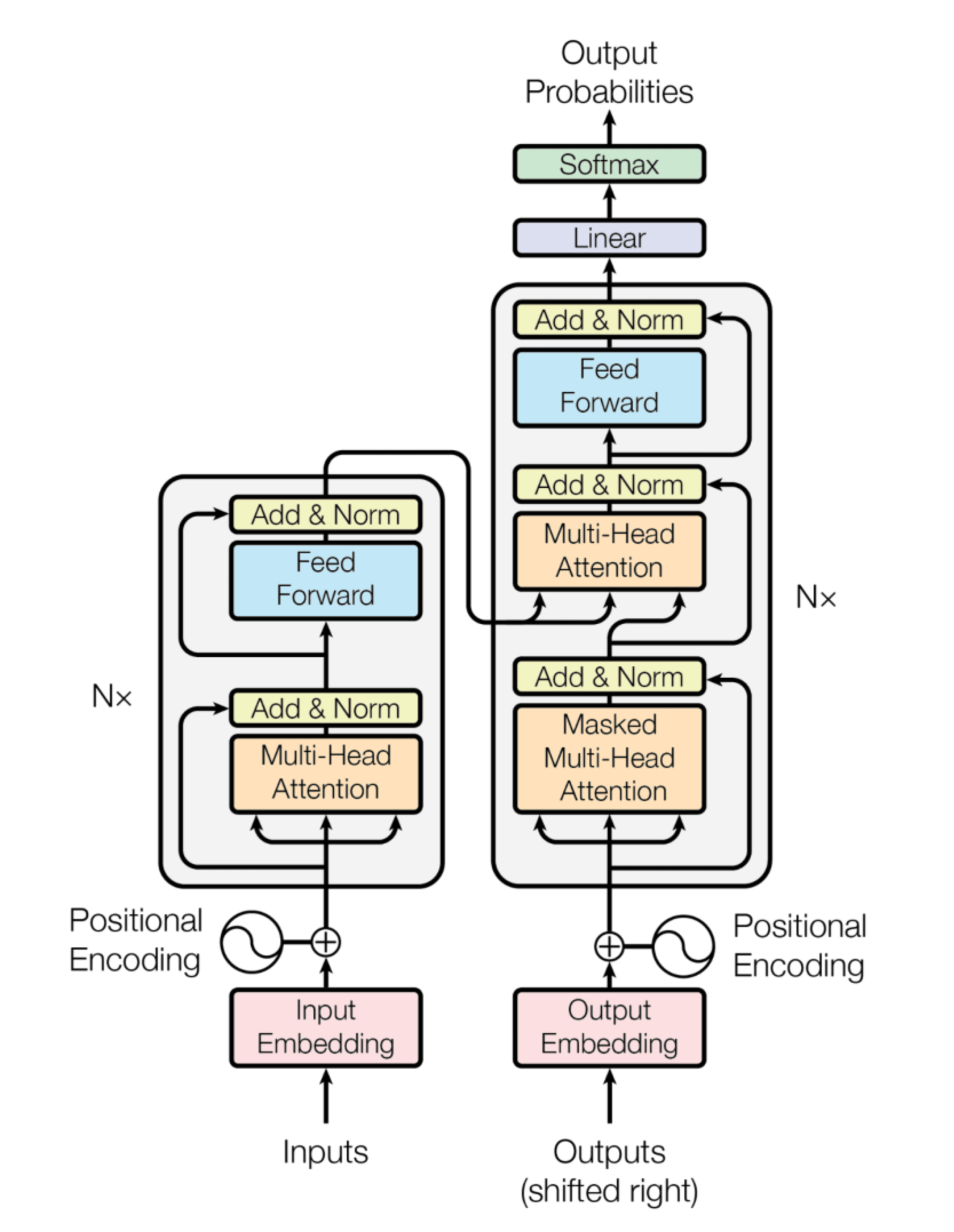
De Transformer architectuur lost het performance probleem op door het coderen en decoderen parallel uit te laten voeren.
Dit is het plaatje van de Transformer model architectuur uit het oorspronkelijke artikel Attention is all you need uit 2017.
Afbeeldingen en schema’s van ‘gewone’ neurale netwerken kom je op internet in allerlei zelfgemaakte varianten tegen. Maar dit plaatje … vrijwel ieder vervolgartikel neemt het ongewijzigd over.
Het is wat mij betreft het grondplan van een digitaal monument, een kathedraal van de AI.
De Transformer architectuur vraagt fors wat toelichting, daar gaat het in volgende berichten over. Ook kijken we naar de technische voorbewerking, de zogenoemde preprocessing, die nodig is om computers aan het werk te zetten met een taalmodel, zowel bij de pre-training als bij het gebruik in de praktijk.