
Dobbelen of matrixrekenen
De tijd zal leren of de impact van AI, en de zoektocht naar AGI, te vergelijken zal zijn met die van de kwantummechanica. Ik durf al wel een aanvulling te doen op een beroemde quote: “God dobbelt niet, Hij vermenigvuldigt matrices“.
De oorspronkelijke uitspraak komt van Einstein, die niet geloofde in natuurkunde waarbij kansberekening een belangrijke rol speelt, zoals bij kwantummechanica. In 1926 schrijft hij aan Max Born “De theorie levert veel op, maar brengt ons nauwelijks dichter bij het geheim van de Oude. Ik ben in ieder geval overtuigd dat Hij niet dobbelt“.
In een artikel over de controverse tussen Einstein en de kwantumfysici kwam ik de uitdrukking ‘half-kennis‘ tegen. Misschien het toenmalige equivalent van A woven web of guesses... Ik heb mijzelf tot doel gesteld uit te zoeken hoe de grote taalmodellen omgaan met hun ‘kennis’ van de wereld. In eerdere berichten vind je uitleg over het attention mechanisme dat belangrijk is in het Transformer model. Een belangrijk element maar conceptueel onvoldoende om het gemodelleerde systeem echt te laten leren. Wiskundig instrumentarium, matrices en matrixrekening, biedt hulp zowel technisch als conceptueel.
Uiteindelijk blijken kansverdelingen toch weer een belangrijke rol spelen, in dit geval in de manier waarop de resultaten van AI tot stand komen.
Formule
Ruim 20 jaar voor zijn twijfel aan de nieuwe inzichten had Einstein zelf een nieuw inzicht vastgelegd over de relatie tussen massa en energie, samengevat:  . De formule is vaak geciteerd, te pas en te onpas wellicht, en is een icoon geworden voor een kantelpunt in de natuurwetenschappen. T-shirt waardig…
. De formule is vaak geciteerd, te pas en te onpas wellicht, en is een icoon geworden voor een kantelpunt in de natuurwetenschappen. T-shirt waardig…

In mijn ogen is de Transformer architectuur ook een kantelpunt, nu in de ontwikkeling van AI. Er hoort ook een formule bij, iets minder catchy dan de formule van Einstein, maar in de toekomst wellicht even iconisch. Attention is all you need is niet voor niets de titel van het oorspronkelijke artikel.

De formule behelst de bewerking en vermenigvuldiging van Q, K en V en dat zijn matrices, vandaar in de aanhef mijn brutale aanvulling op de quote. In andere berichten probeer ik er achter te komen hoe het in elkaar zit, maar in dit bericht laat ik de techniek achterwege en focus ik op de rol die matrices als wiskundig hulpmiddel en als drager van gedachtengoed vervullen.
Matrices
Waar komen matrices tevoorschijn? Het attention mechanisme in de Transformer architectuur levert iets op dat we gewichten noemen, maar die slechts putten uit gedetermineerde, onveranderlijke, waarden binnen de context en getrainde inhoud van het taalmodel. Er kan op dat moment met het Transformer deep learning model nog niets ‘geleerd’ worden.
In de modellering wordt het opgelost door de introductie van matrices waarin de vectoren zijn ingebed. Die matrices bevatten veranderbare gewichten die met deep learning aangeleerd kunnen worden.
Van een afstandje bekeken is er geen directe inhoudelijke of intrinsieke relatie tussen matrices en deep learning. Matrices lijken in dit opzicht ‘inhoudsvrij’ te zijn. Dat maakt ze tot geschikte wiskundige hulpmiddelen, vehikels die voor de gelegenheid worden geladen met de conceptuele inhoud van het domein, vertaald in vectoren, scores en gewichten. En daarna kan je er gewoon mee rekenen, natuurlijk.
Door te werken met matrices kan bovendien in het Transformer model het enkelvoudige attention mechanisme worden gegeneraliseerd naar een Multi-Head attention. Alle er mee gemoeide informatie wordt bij elkaar ‘onthouden’ en – zeer belangrijk voor de performance van dit soort systemen – in parallel getransformeerd.
In het geval van de meerdere heads gebeurt dat wiskundig gezien door concatenatie van de matrices. Simpel gezegd: ze worden letterlijk aan elkaar geplakt tot een nieuwe matrix. Ook met die nieuwe matrix kun je rekenen, maar en passant gebeurt er iets spectaculairs. Veronderstel dat een enkelvoudig attention mechanisme (single head) 2-dimensionale matrices gebruikt. Met, bijvoorbeeld, 3 heads zorgt de concatenatie er voor dat er een 6-dimensionale matrix ontstaat. Zo’n matrix ‘leeft’ in een eveneens 6-dimensionale vectorruimte waar concepten als dot product en cosine similarity gewoon hun betekenis behouden maar waar het menselijk voorstellingsvermogen het al snel moet laten afweten.
Het meest waarschijnlijke volgende woord
Het totale schema uit het oorspronkelijke artikel zie je hier, encoders staan links, decoders rechts. Aan beide kanten staat “Nx”, dat wil zeggen dat eenzelfde onderdeel N maal herhaald wordt, afhankelijk van de complexiteit van de situatie. In het artikel is N=6.
Voor uitleg verwijs ik naar elders, hier wil ik het hebben over de uitvoer die je rechtsboven ziet staan, Output Probabilities. Die uitvoer wordt volgens het schema geproduceerd door een Softmax component en een Linear component die werken op de output die de decoder verlaat, output die bijna volledig met matrixberekeningen tot stand is gekomen.
De Linear laag is een volledig verbonden neuraal netwerk (een zg. dense neural network) die de contextvectoren die uit de decoder komen omzet in een veel grotere vector. Deze vector bevat scores van alle mogelijke uitkomsten die het taalmodel kent – een zeer ruime verzameling tokens – die in relatie zijn gebracht met de contextvectoren.
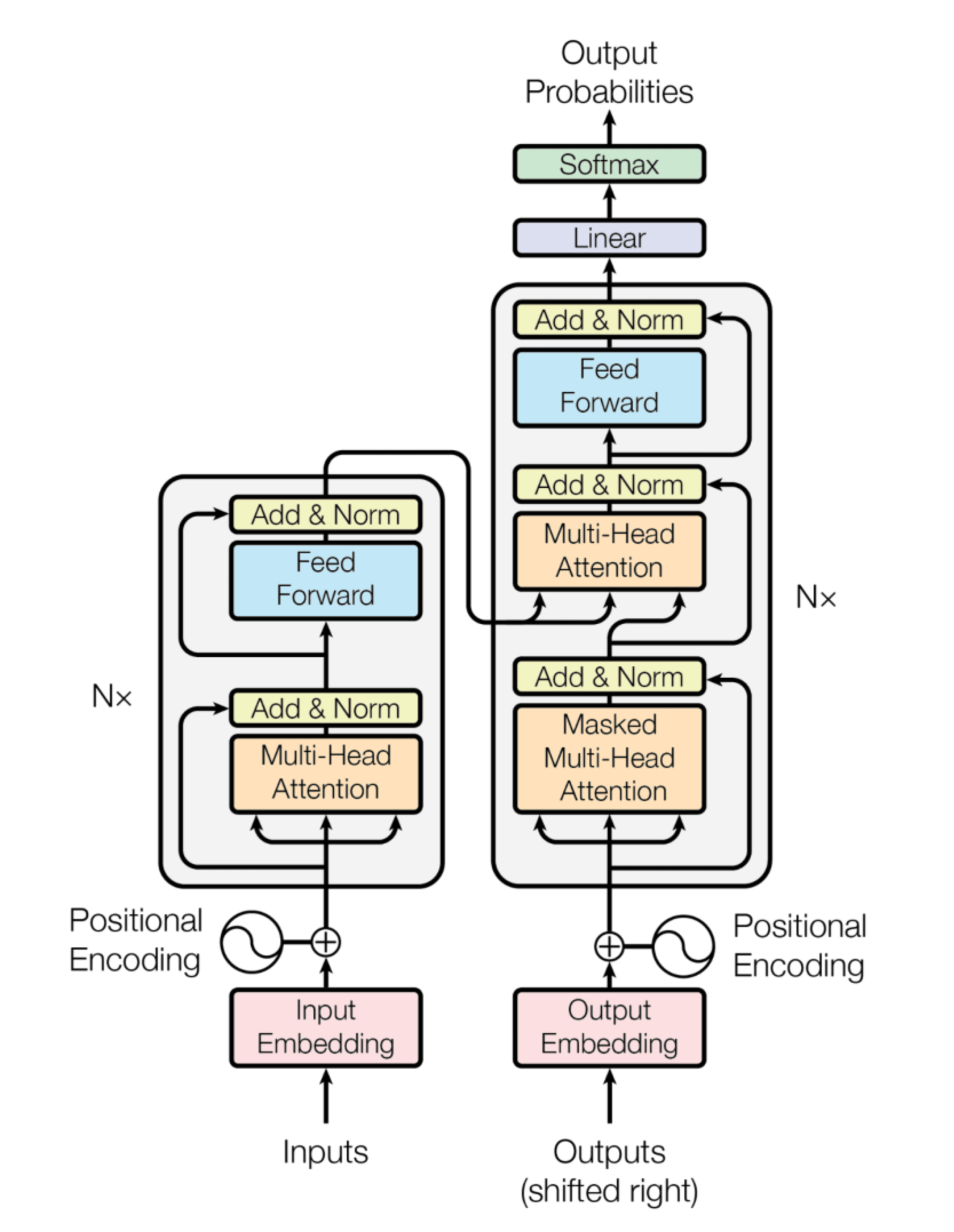
Voor het geval die scores getalsmatig nog alle kanten opgaan, maakt de Softmax laag er een keurig genormaliseerde kansverdeling van (i.e. waarden tussen 0 en 1, bij elkaar opgeteld gelijk aan 1). Zo is het toch weer dobbelen geworden: de hoogste waarde in die verdeling geeft de voorspelling voor het meest plausibele volgende woord, niet voor het ‘zekere‘ vervolg. Einstein zou misschien niet tevreden zijn…
Een treffende overeenkomst
In de jaren (19)20 werkte Heisenberg aan een theorie om energieniveaus en kwantumsprongen met elkaar te verbinden. Formules en berekeningen bij de vleet, maar hij kreeg de theorie niet passend bij de getallen die hij met de berekeningen vond. Met name de volgorde waarin die berekeningen werden gedaan bleek van invloed op de resultaten die hij kreeg.
Heisenberg durfde zijn bevindingen niet voor publicatie aan te bieden, maar hij stuurde het hele pakket naar Max Born (dezelfde die in 1926 de niet-dobbelen brief van Einstein kreeg). Born stelde voor om de getallen door matrices te vervangen, daarmee werd in elk geval de invloed van volgorde in berekenen meteen goed gemodelleerd. Matrixvermenigvuldiging is niet commutatief zoals dat heet, volgorde doet er toe. Bij 2 matrices A en B is de uitkomst van A x B een andere dan van B x A.
Deze modellering leidt uiteindelijk tot het onzekerheidsprincipe van Heisenberg. In mijn woorden: een fysische werkelijkheid bestaat niet los van de manier waarop deze is waargenomen en is afhankelijk van de volgorde van bepaalde waarnemingen.
Als onverbeterlijk romanticus zie ik een parallel. Ook in het geval van Heisenberg/Born wordt de matrix en matrixrekening als vehikel voor – in dit geval kwantumfysische – inhoud naar binnen gehaald. De matrices zijn vervolgens de vastlegging van waarschijnlijkheden, van kansverdelingen – precies dat waar Einstein zich in de brief van 1926 tegen verzet had.
Wellicht is er helemaal geen parallel, maar ik neem in elk geval de kans te baat om een geweldige, zeer tot mijn verbeelding sprekende, foto te laten zien. Op de foto staan de 29 deelnemers aan de 5e Solvay conferentie van 1927, een jaar na de God-dobbelt-niet uitspraak van Einstein. Ze spreken daar over de kwantumfysica, met name over het onzekerheidsprincipe van Heisenberg en de golf-of-deeltje opvattingen. Er zijn een paar facties daar, die het beslist niet met elkaar eens zijn, maar op de groepsfoto zie je er niks van.

De foto is een geweldig zoekplaatje, wie staan er op? Nou ja, de namen staan er onder – ik verklap dat hier een halve Nobelprijzenpot bij elkaar op de foto is gegaan, 17 van de 29 aanwezigen hebben ooit een Nobelprijs gekregen. En Madame Curie telt dubbel, zij kreeg er twee.
Ook de door mij opgevoerde actoren zijn er: Einstein, niet te missen vooraan, en Heisenberg en Born aan de rechterkant.
Hoe mooi zou het zijn om een hedendaagse variant van de foto te maken, met alle kopstukken, spraakmakers en deskundigen bijeen om over de richting van AI ontwikkeling te confereren? Ik ben benieuwd hoeveel vrouwen er op die foto zouden staan, maar optimistisch over dat aantal ben ik niet.