Omduwen
Een taalmodel levert resultaat op basis van next-token prediction, het voorspellen van het meest plausibele vervolg van een tekst. Ik wil achterhalen hoe dat technisch gezien in zijn werk gaat. Het is een deel van de licht wiskundige uitwerking die ik eerder aankondigde.
Een succesvolle voorspelling is afhankelijk van de context waarin deze moet gaan passen – de eerdere woorden en de wijze waarop die zich tot elkaar verhouden bepalen als het ware de plausibiliteit. Die verhouding van woorden tot elkaar betreft niet alleen grammaticale samenhang maar ook semantische.
De betekenis van een woord haalt een taalmodel voor een deel uit wat het eerder ‘geleerd’ heeft, maar is mede afhankelijk van de woorden die in de actuele context in de omgeving van dat woord staan.
Bronnen: mijn uitleg hieronder is gebaseerd op veel artikelen en online tutorials. Ik heb veel gehad aan Intuition Behind Self-Attention Mechanism in Transformer Networks, een voortreffelijke video van Arkar Min Aung, waarin hij stapsgewijs laat zien wat er moet gebeuren om een taalmodel zijn werk te laten doen. Aan hem credits voor de uitleg en voor afbeeldingen waarvan ik er een aantal hieronder gebruik.
Dit is de inhoud van dit lange bericht:
- Semantische overeenkomsten
- Attention mechanisme
- Inproduct (dot product)
- Normalisatie
- Omduwen met gewichten
- Voorbeeld
Semantische overeenkomsten
Ik kom er steeds vaker achter dat ontwikkelingen en inzichten op AI gebied, waarvan je denkt dat ze nieuw zijn en aangeslingerd in de recente ontwikkelingsversnelling, een herkomst hebben die tientallen jaren teruggaat. De uitspraak “You shall know a word by the company it keeps” lijkt een goede samenvatting van wat de nieuwe taalmodellen doen, maar is afkomstig uit het boek A Synopsis of Linguistic Theory (1957) van J.R. Firth.
Het werk van Firth markeert het begin van een onderzoeksterrein dat distributional semantics – distributionele semantiek – wordt genoemd. Het draait er om semantische overeenkomsten tussen taalkundige items te kwantificeren en te categoriseren op basis van hun verdeling in tekstcorpora. De hypothese is: taalkundige items met een overeenkomstige verdeling hebben een overeenkomstige betekenis.
De komst van grote computers met veel rekenkracht heeft de hypothese ook instrumenteel gemaakt, met verdelingen van taalitems uit gigantische tekstcorpora in hoog-dimensionale ruimtes (512 dimensies is tegenwoordig tamelijk gangbaar). Het intuïtieve karakter van de hypothese is daarmee wel een beetje verloren gegaan, daarom gebruik ik een paar eenvoudige voorbeelden om te laten zien hoe taalmodellen omgaan met betekenisverwantschap.
Allereerst een Engelstalig voorbeeld uit de hiervoor genoemde video, we concentreren ons op het woordje bank in de volgende twee zinnen:
I swam across the river to get to the other bank
I drove across the road to get tot the other bank
De context maakt het plausibel dat bank in de eerste zin de oever van een rivier betreft, en in de tweede zin waarschijnlijk een financiële instelling. Mensenogen zien de aanwijzingen meteen, in de combinatie van bank met swam en river in de eerste zin, en met drove en road in de tweede.
Taalmodellen hebben miljoenen van dit soort zinnen verwerkt maar missen de mogelijkheid verbanden in één oogopslag te ‘zien’. In plaats daarvan hebben ze de woorden uit de tekstcorpora waarop ze getraind zijn als vectoren opgeslagen in een N-dimensionale semantische ruimte. De vector van een woord bestaat uit het indexgetal van het bijbehorende token, en getalsmatige ‘scores‘ van dat woord op een groot aantal (N) eigenschappen (meestal features genoemd).
Het taalmodel is in staat aan de hand van de vectoren te bepalen in welke mate woorden verband houden met andere woorden in het corpus. In de context van generatieve AI wordt vaak de ‘hoek’ tussen woordvectoren als maat voor verwantschap gebruikt, de zogenoemde cosine similarity. Verderop geef ik een 2-dimensionaal voorbeeld waaruit de rol van de cosinus van de hoek tussen vectoren blijkt, wiskundig gezien maakt het geen verschil of het om 2 of N dimensies gaat.
Op het gebied van woordvectoren is een aantal manieren gevonden om je een voorstelling te kunnen maken van woordvectorruimtes van hoge dimensie. Een publiek toegankelijke vectorruimte is Word2Vec. De oorsprong gaat terug tot 2013 toen het werd gepubliceerd door onderzoekers van Google. Met behulp van TensorfFlow.js (een verzameling wiskundige routines in JavaScript) is een visualisatie gemaakt die je kunt bekijken in je browser, ga naar: Embedding Projector.
Het komt er op neer dat je in een gigantische puntenwolk, een woordenwolk, kunt ‘kijken’. Neem ‘in‘ letterlijk: je kunt elk punt in de wolk aanklikken. Je krijgt dan te zien wat de frequentie van het woord is in het corpus en ook, voor ons doel belangrijker, wat de dichtstbijzijnde woorden in het corpus zijn volgens de cosine similarity.
In zekere zin kijk je naar de ‘pijlpunten’ van de vectoren. Je kunt inzoomen op de wolk, draaien langs verschillende assen, selecteren, doorklikken naar andere woorden, …. Het verkennen van Word2Vec is licht verslavend.
De afbeelding laat zien hoe de wolk eruit ziet in de nabijheid van het woord ‘bank‘. In het corpus van 71.291 (verschillende) woorden komt bank 1.806 keer voor. Voor de overzichtelijkheid heb ik ingesteld dat de 100 dichtstbijzijnde woorden worden getoond.
Als je de afbeelding groter maakt (een keer klikken) zie je bank, en een cluster woorden uit de financieel-economische hoek. Rechtsboven zie je toch ook woorden die met ‘water’ te maken hebben (coast, river, canal, …).
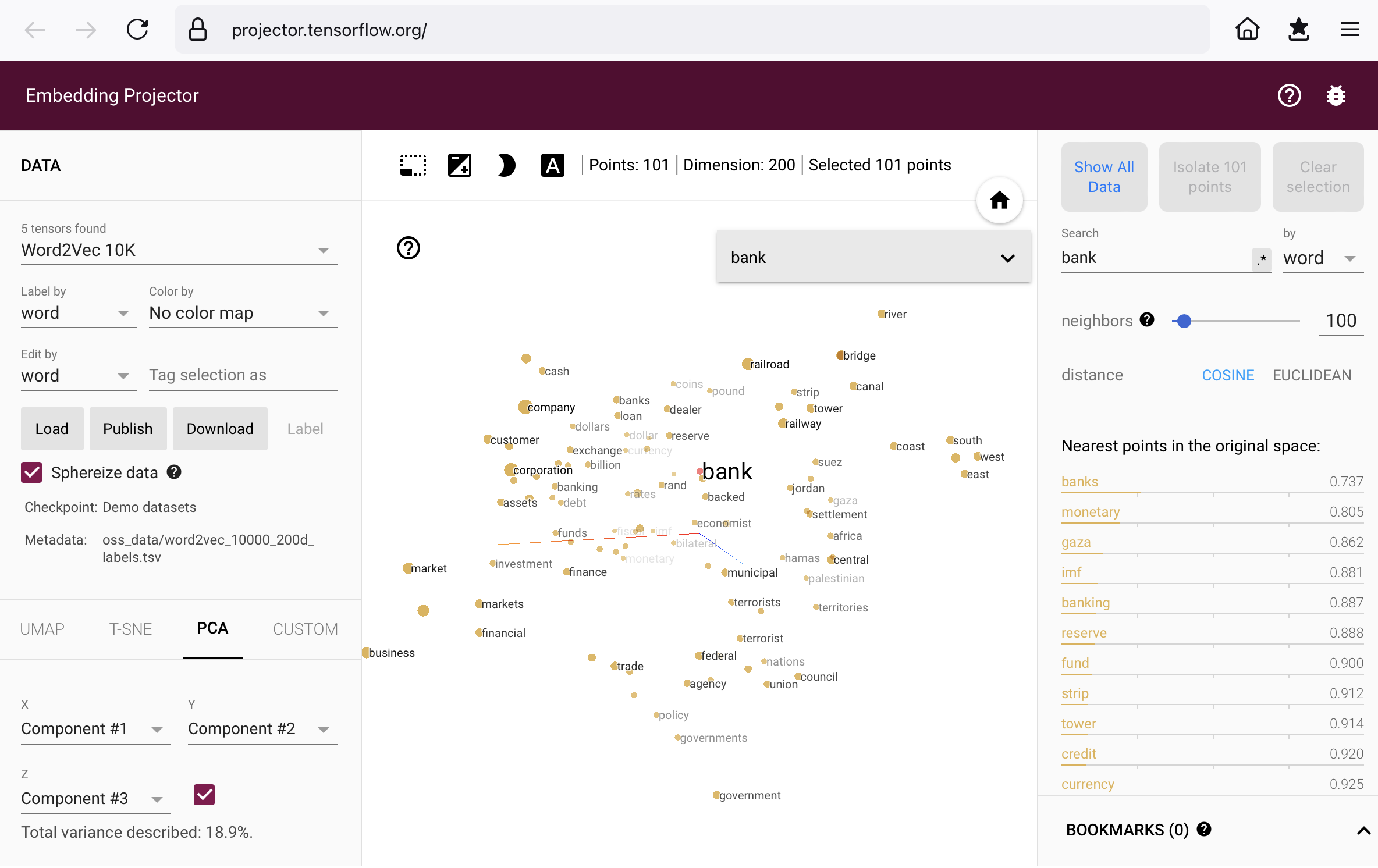
Je kijkt in zekere zin naar waar de vectorpunten van de woorden uitkomen. Als je een taalmodel zonder meer zou loslaten op onze voorbeeldzin dan zou het op basis van frequentie en verwantschap de meeste plausibiliteit zien in de financieel-economische betekenis van bank.
Eigenlijk zou je de vectorpunt van het woord bank in onze zin willen omduwen, opschuiven in de richting van het cluster dat met water te maken heeft. Dat nu is volgens mij precies wat de grote taalmodellen mogelijk maken, in de chat modus zeg maar. Daar immers geef je als gebruiker de context aan waarin de plausibele betekenis van een woord moet passen. De veelgenoemde en geroemde prompt.
Attention mechanisme
Laten we eens zien hoe dat ‘omduwen’ bewerkstelligd kan worden. Eigenlijk gaat het om het verdraaien van de woordvector, om op die manier de betekenis te verschuiven. We kijken onder de motorkap.
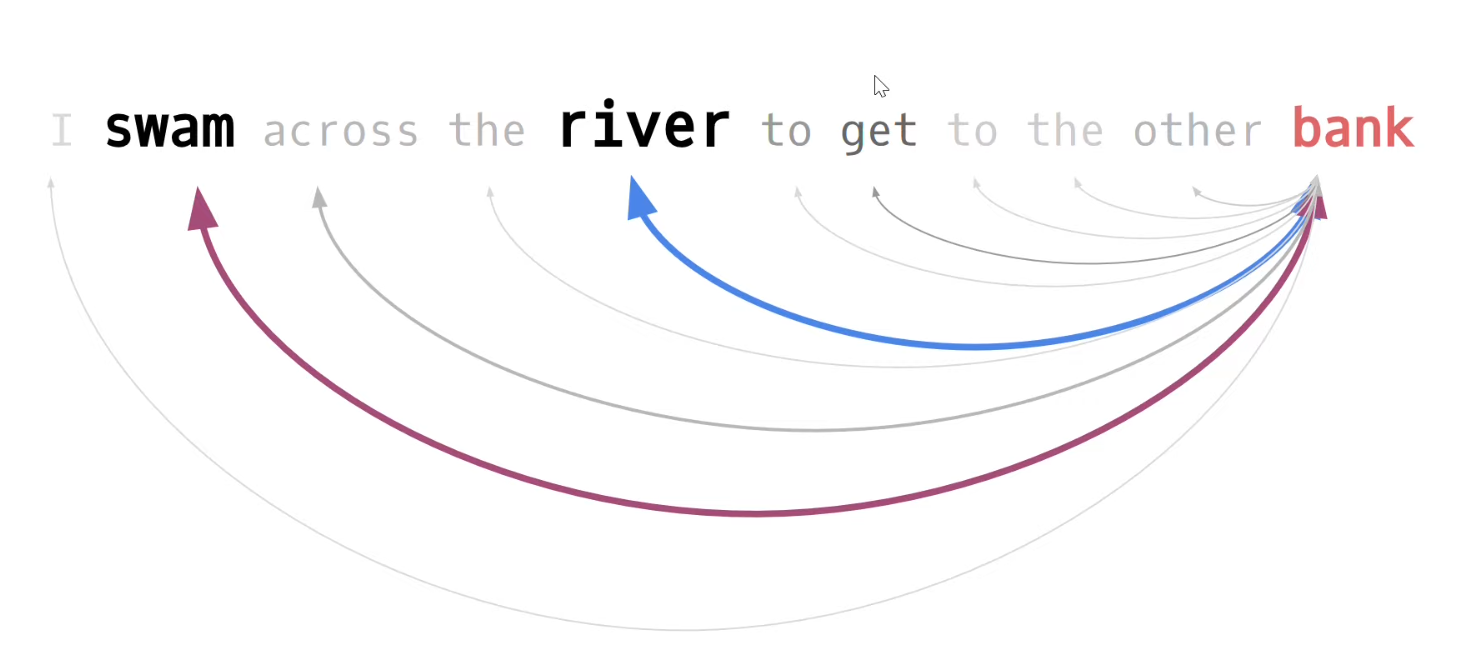
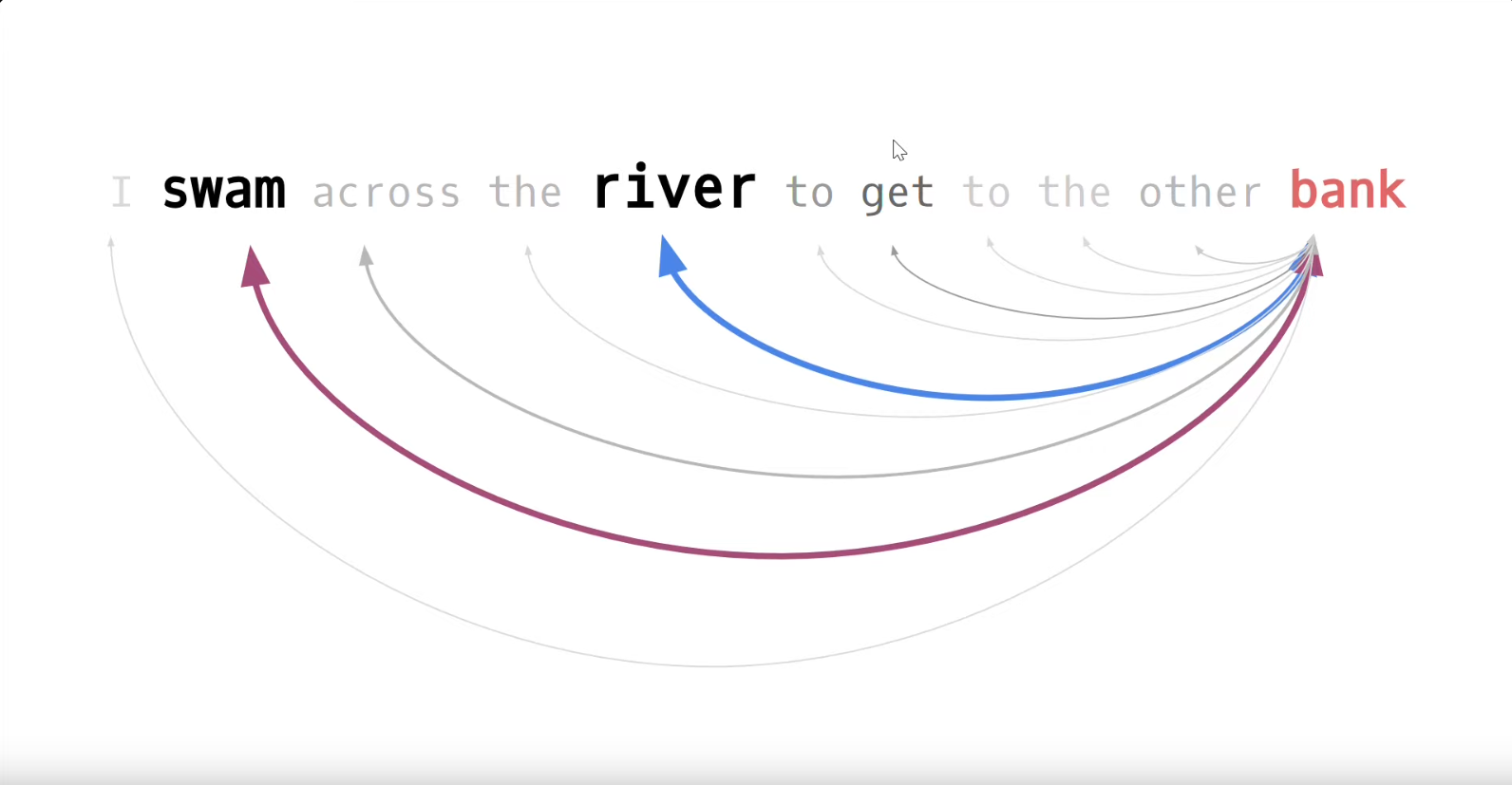
Voor ons voorbeeld zou je willen dat er vanuit het woord bank (blijvende) ‘aandacht’ is voor de andere woorden in de tekst die immers meer of minder gewicht in de schaal leggen voor de betekenis. Het liefst zou je de relatie van bank met alle andere woorden in de context willen beoordelen, willen scoren.
In het plaatje geven kleur en dikte van de pijlen al een suggestie van het gewicht van de onderlinge verhoudingen met het woord bank.
We volgen de stappen die ik eerder als voorbereidingen in de preprocessing pipeline heb benoemd.
Voor onze voorbeeldzin halen we vervolgens voor elk woord de woordvector op uit de (een) semantische vectorruimte.
NB Alle grote taalmodellen (GPT, Claude, Bard, andere) hebben hun eigen semantische vectorruimtes, gebaseerd op het tekstcorpus waarop het getraind is.
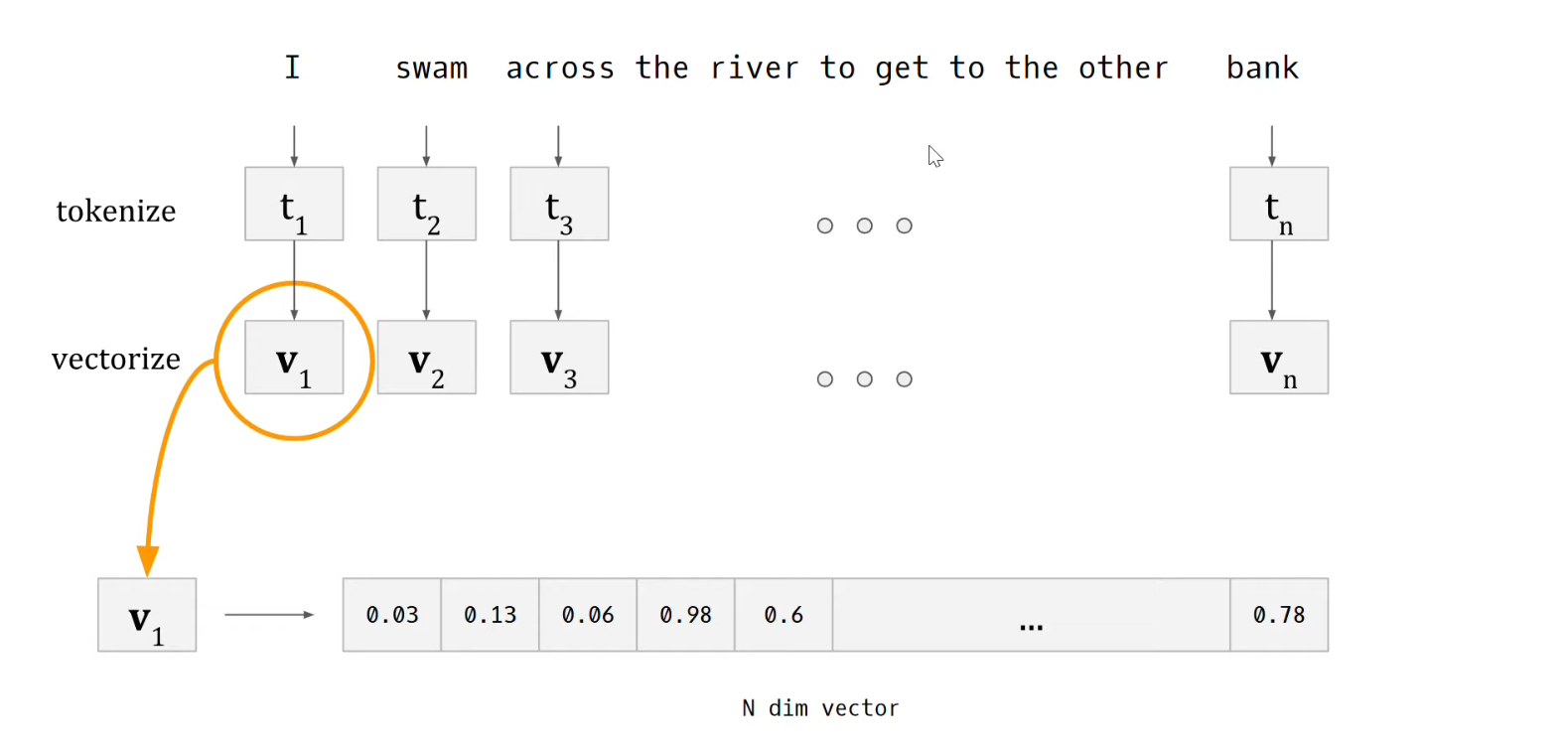
Het is niet toevallig dat het begrip ‘attention’ al in meerdere berichten aan bod is geweest, maar nu wil ik uitvinden hoe je concreet contextuele informatie kan toevoegen aan (alle) woorden in een zin.
We verschuiven, verdraaien, de vector v van elk woord in de tekst naar een gecontextualiseerde versie, vector y. Hierbij is aandacht voor de hele tekst, want het moet een weerspiegeling zijn van het belang van elk woord voor het geheel. Het mechanisme heet self-attention.
Hoe gaat het in zijn werk? In de afbeelding is schematisch weergegeven welke stappen je moet volgen om de v-vectoren te transformeren in y-vectoren waarin de context is meegenomen. Elke stap vergt wat uitleg, die hieronder in drie episodes volgt.
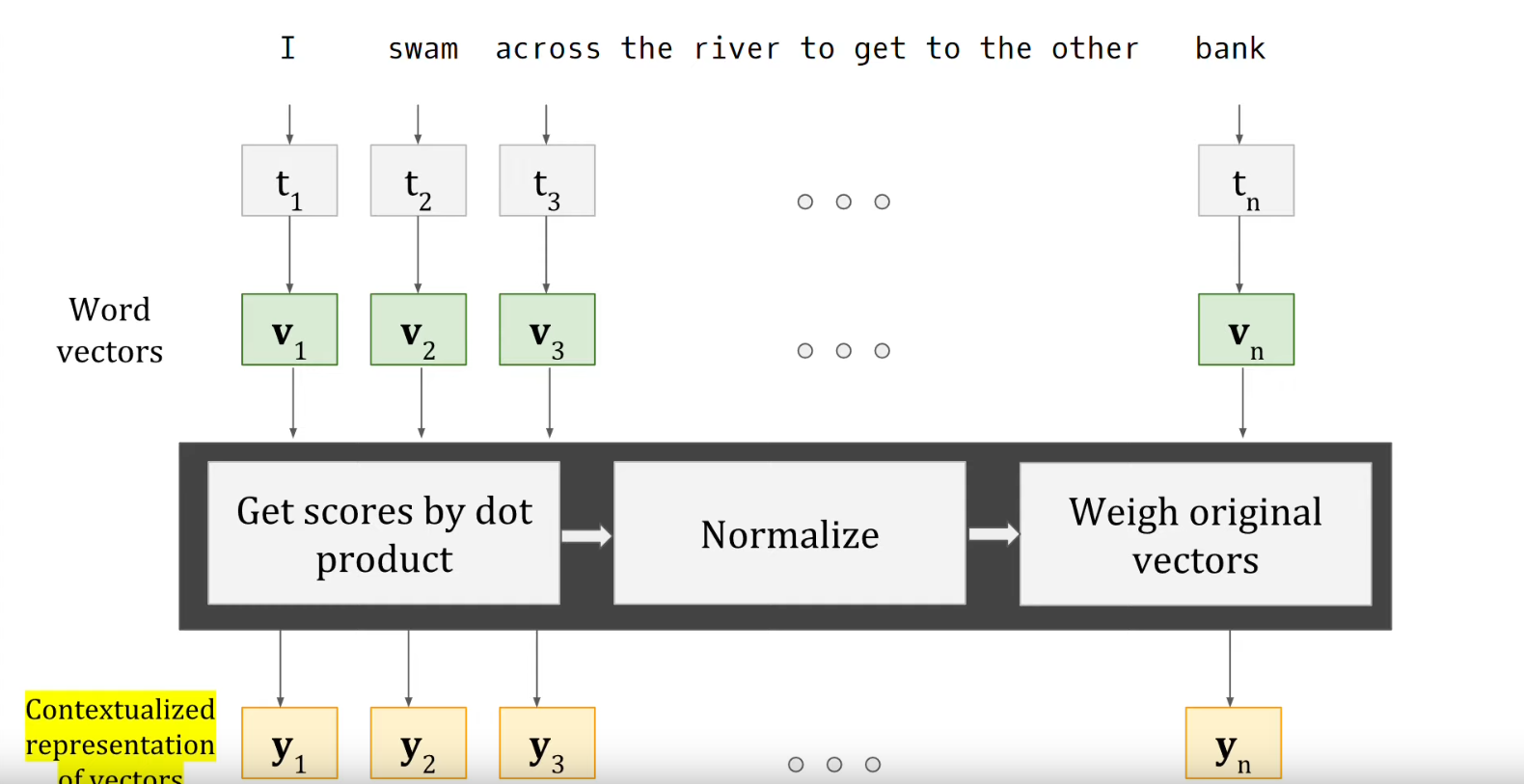
Episode 1: inproduct scores van vectoren
Zoals gezegd zouden we graag de relatie van bank met de andere woorden in de tekst op belang willen beoordelen, willen ‘scoren’. En als we toch bezig zijn misschien maar meteen de relatie van elk woord uit de tekst met elk ander woord in de tekst.
In de grote vectorruimte werd de hoek van twee vectoren als maat gebruikt om verwantschap te bepalen, de cosine similarity. Ons doel om woordvectoren te verdraaien in de richting van verwante vectoren moet dus in die hoek tot uitdrukking komen.
Er is een 1-op-1 relatie tussen de hoek van twee vectoren en het zogenoemde dot product van die vectoren, in goed Nederlands het inproduct. Ook het inproduct is dus een maat voor verwantschap én het is een (dimensieloos) getal, een scalair. Daar houden computers van.
Het inproduct van twee vectoren wordt berekend met de formule

Bijvangst van de formule is dat je kunt zien dat het inproduct van de eerste vector met de tweede vector gelijk is aan het inproduct van de tweede vector met de eerste vector, het inproduct is commutatief.
Het verband tussen de hoek van twee vectoren en hun inproduct voert naar de cosinus van die hoek, daar komt de term cosine similarity vandaan. Met  als hoek tussen twee vectoren p en q is de formule:
als hoek tussen twee vectoren p en q is de formule:
 waarbij
waarbij  het inproduct is en
het inproduct is en  en
en  de lengtes van de vectoren
de lengtes van de vectoren
Als twee vectoren samenvallen is de uitkomst van de breuk 1, de hoek is dan 0 graden. Als de cosinus 0 is is de hoek 90 graden, de vectoren staan dan loodrecht op elkaar en zijn het minst verwant.
Als regel geldt: hoe groter het inproduct hoe groter de cosinus, des te kleiner de hoek en des te groter de verwantschap.
Technisch gezien is het inproduct een matrix vermenigvuldiging van een 1xN matrix met een Nx1 matrix, waarbij N de dimensie van de vector is.
Hierboven gebruikte ik steeds de punt, de dot van dot vector, in de notatie voor het inproduct .
Als matrix vermenigvuldiging schrijf je:  . De T staat voor getransponeerd. Je transponeert een matrix door de oorspronkelijke rijen als kolommen te nemen, en de oorspronkelijke kolommen als rijen, steeds met dezelfde inhoud van de velden.
. De T staat voor getransponeerd. Je transponeert een matrix door de oorspronkelijke rijen als kolommen te nemen, en de oorspronkelijke kolommen als rijen, steeds met dezelfde inhoud van de velden.
Terug naar het contextualiseren van onze oorspronkelijke zin. We hebben de woorden in de zin voorzien van woordvectoren waarin eigenschappen van de woorden (eigenlijk de tokens) getalsmatig zijn vastgelegd.
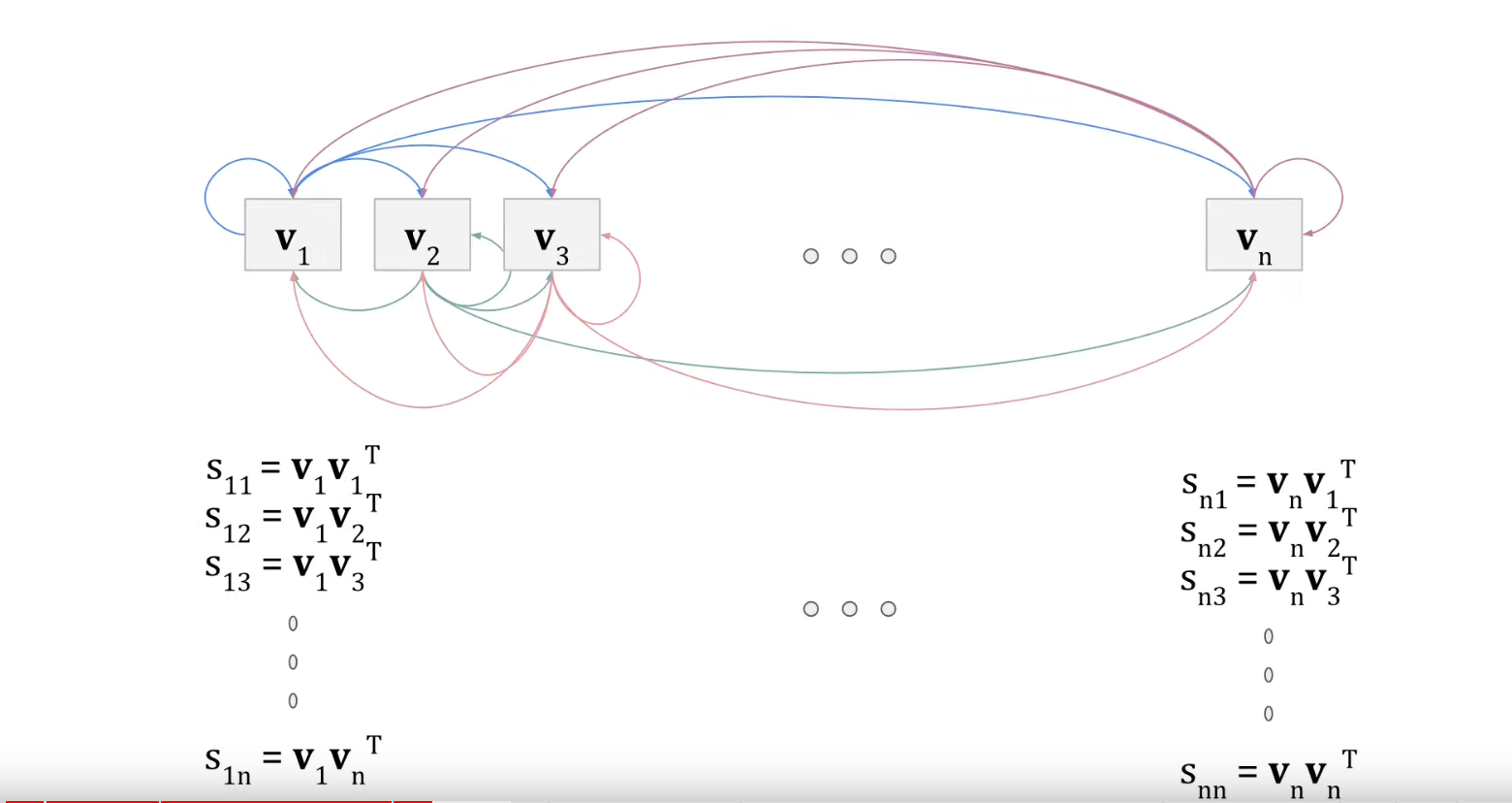
De wens om de relatie van bank met alle andere woorden in de context te beoordelen, te scoren, stond hierboven al in een plaatje zoals links.
Het plaatje rechts geeft weer hoe we die scores kunnen bepalen: met het inproduct van elke vector met elke andere vector.
NB In het plaatje is de matrix notatie gebruikt.
Voor de scores geldt: bij grote onderlinge verwantschap een hoge waarde van het inproduct, de score, bij geringe verwantschap een lage score. En alles er tussen in.
Een vaak gebruikte visualisering van dit soort scores is een tabel met grijswaarden. Hoe lichter de cel, hoe groter de verwantschap. Wordt ook wel heat map genoemd (maar dan worden meestal kleuren gebruikt).
Omdat ook elk woord met zichzelf in verband is gebracht via het inproduct zie je op de diagonaal de grootste verwantschap. Het deel boven de diagonaal en het deel er onder zijn elkaars gespiegelde.

Episode 2: normalisatie
Op de rijen in de tabel staan de uit inproduct verkregen scores. In de schrijfwijze van hierboven staan op rij 1 achtereenvolgens  . En zo door voor de 2e rij met
. En zo door voor de 2e rij met  , enzovoorts. De waarde rechtsonder is
, enzovoorts. De waarde rechtsonder is  .
.
Omdat de scores afkomstig zijn van inproducten van vectoren van velerlei herkomst kunnen de waarden alle kanten opvliegen. Vergelijkbaarheid is ver te zoeken, terwijl die wel wenselijk is in de context van taalmodellen die voor alle prompts moeten werken. Het wiskundige toverwoord in dit soort situaties is: normaliseren. Dat is, zeg maar, het op een zodanig inzichtelijke en algemeen toepasbare manier aanpassen van (getal)waarden dat ze onderling vergelijkbaar worden.
Er is een aantal goede redenen om het zo te doen dat alle waarden
– positieve getallen worden in het bereik ![[0..1]](https://corsai.ronde3.nl/wp-content/ql-cache/quicklatex.com-30fe77b3b615f183d093ea98ada1f597_l3.png "Rendered by QuickLaTeX.com")
– de som van alle waarden op een bij de context horende reeks waarden, zoals een rij in de tabel, gelijk is aan 1.
Bij een toverwoord hoort een toverformule, en die is er ook – in de gedaante van de Softmax-functie. De functie in formule vorm is als volgt:

Het voert hier te ver om te laten zien dat de formule doet wat we er van verlangen, maar je kunt aan de formule zien dat je op precies 1 uitkomt als je alle breuken  tot en met
tot en met  bij elkaar optelt.
bij elkaar optelt.
Met behulp van deze normalisatie vormen we al onze scores  tot en met om, tot gewichten
tot en met om, tot gewichten  .
.
 tot en met
tot en met 
Episode 3: woordvectoren omduwen met gewichten
We zijn nu bijna waar we willen zijn. In onze voorbeeldzin hebben we alle woorden met elkaar in verband gebracht door middel van verwantschap-scores afkomstig van de inproducten van de semantische woordvectoren van de woorden in de zin. We hebben die scores onderling vergelijkbaar gemaakt met de softmax-functie zodat we nu vergelijkbare gewichten hebben. We weten nu letterlijk welk gewicht elk woord in de context in de schaal legt.
Met die gewichten kunnen we de gecontextualiseerde woordvectoren maken, dat zijn in onze metafoor de ‘omgeduwde’ vectoren, als volgt:

…

Bedenk dat alle gewichten  scalairen zijn, tussen 0 en 1, en dat ze opgeteld per regel samen 1 zijn.
scalairen zijn, tussen 0 en 1, en dat ze opgeteld per regel samen 1 zijn.
Per woord uit de context met woordvector  hebben we nu een ‘omgeduwde’ betekenis, een verdraaide vector
hebben we nu een ‘omgeduwde’ betekenis, een verdraaide vector  , gemaakt op basis van de invloed van alle andere woorden in de context. Dat is het self-attention mechanisme.
, gemaakt op basis van de invloed van alle andere woorden in de context. Dat is het self-attention mechanisme.
Ter illustratie
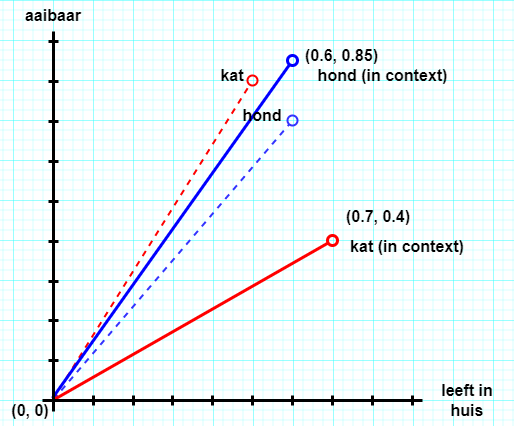
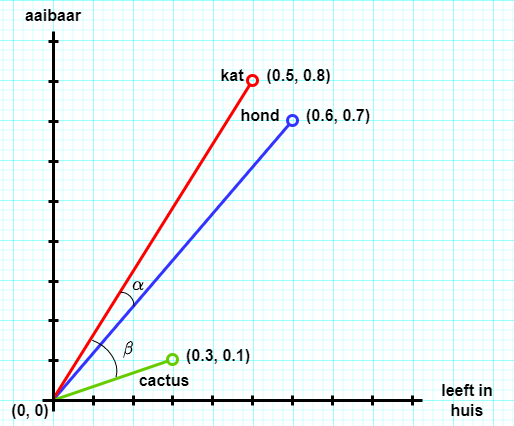
Een voorbeeld in 2 dimensies. Stel, we hebben drie woorden in een corpus (kat, hond, cactus) die elk een woordvector hebben met een getalswaarde voor twee eigenschappen (leeft in huis, aaibaar).
De inproducten in ons tweedimensionale voorbeeld laten zich eenvoudig berekenen.



Kat en hond hebben onderling veruit de grootste verwantschap als het om de eigenschappen leeft in huis en aaibaar gaat. Met de gegeven waarden is de kat het meest aaibaar.
De semantische vectorruimte zou er zo uit kunnen zien:
Nu wil ik de vectoren omduwen. In dit (fictieve) voorbeeld geef ik een prompt voor een taalmodel met de (even fictieve) waarden van eigenschappen van hond en kat in zijn semantische vectorruimte. De prompt heeft de vorm van een invuloefening, in het jargon een ‘gatentekst’ (cloze test in het Engels).
1
Mijn buurman heeft een hond en een kat. Als ik ‘s avonds langs zijn huis loop zie ik hem op de bank naar tv kijken. Op de mat naast de bank zit zijn ….. die hij graag mag aaien.
> Vul in wat er op de puntjes staat.
Met de gegeven waarden in de semantische ruimte van het taalmodel ligt het voor de hand dat het model kat als de meest plausibele keuze ziet.


2
Ik vul de prompt aan met de vermelding dat de hond een Labradoodle is, en de kat van het haarloze ras Sphynx. Zie de fotootjes.
Labradoodle en Sphynx hebben hun eigen semantische vectoren, misschien wel (0.7, 0.4) voor de kat en (0.6, 0.85) voor de hond. De nieuwe informatie geeft contextuele gewichten waarvan de toepassing kan leiden tot het omduwen, verdraaien, van de oorspronkelijke vectoren voor kat en hond naar de meer specifieke van Labradoodle en Spynx. Met misschien een andere voorspelling voor de gatentekst.
NB Het voorbeeld schiet tekort omdat er geen semantiek voor de overige woorden in de context in zit, de berekening van gewichten zoals hierboven valt daardoor niet zonder meer te maken. Het concept van de context afhankelijke verdraaiing van een semantische woordvector blijft wel geldig.