
Transformer
De Transformer architectuur is een kantelpunt in de ontwikkeling van AI. Attention is all you need is de titel van het oorspronkelijke artikel waarin de architectuur wordt gepresenteerd, een titel die misschien wat verhullend is. Alsof de auteurs nog niet zeker zijn van de impact van hun artikel en de erin beschreven architectuur. Het concept attention was in 2016 zelfs al niet meer nieuw.
Wel nieuw is de uitwerking, de architectuur, waarvan de formule het topje van de ijsberg is.

De formule behelst de bewerking en vermenigvuldiging van de matrices Q, K en V. Ik wil proberen er achter te komen hoe het in elkaar zit.
Wat de impact betreft: feit is dat in de periode van 5 jaar na het verschijnen van het artikel niemand in de wereld van AI het nodig heeft gevonden om wijzigingen in de architectuur voor te stellen.
Scaled Dot-Product Attention
In het oorspronkelijke artikel over de Transformer architectuur staan drie schema’s:
- Scaled Dot-Product Attention
- Multi-Head Attention
- Overzicht van de architectuur met encoder-decoder
Samen met een voorziening om de posities van woorden in een context te bewaren zijn dit de basiscomponenten van de Transformer architectuur.
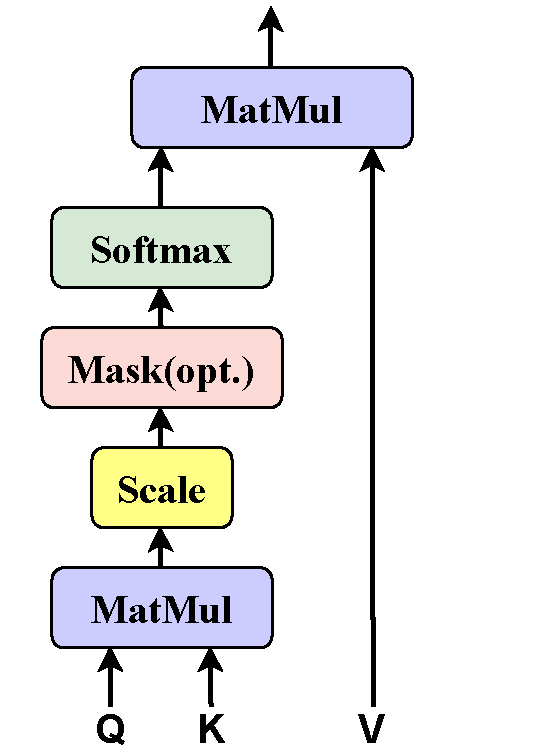
Allereerst de Scaled Dot-product Attention, zie het plaatje. Je ziet, als een soort van input daar de letters Q, K en V al staan. Het zijn matrices zoals gezegd. Wat ze doen en waar ze vandaan komen lees je verderop.
Informele uitwerking
Attention mechanisme (informeel)
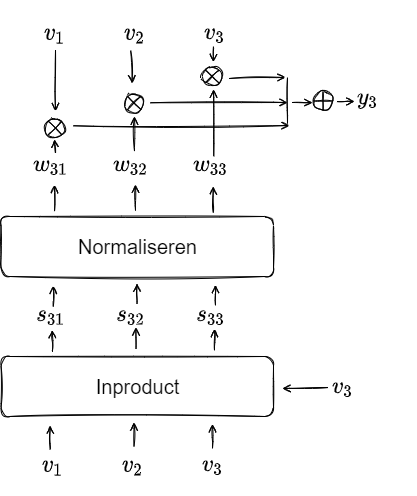
Het plaatje hiernaast geeft op een informele manier het mechanisme Attention weer. In een eerder bericht staat het wat verder uitgewerkt en staan ook de termen toegelicht.
Weergegeven zijn 3 woordvectoren van woorden (tokens) uit een context. Op zoek naar de mate van verwantschap tussen de woorden geven we er scores aan door het inproduct te nemen van elk van de vectoren met de andere (inclusief zichzelf). In het plaatje staat het voor  weergegeven.
weergegeven.
Na een normaliseringsslag krijgen we gewichten tussen 0 en 1. Vermenigvuldigd met de oorspronkelijke vectoren en daarna opgeteld krijgen we vector  (bij ). Zo ook voor de andere vectoren.
(bij ). Zo ook voor de andere vectoren.
Het geheel van bewerkingen heet het Attention mechanisme, en het maakt van de directe representatie van een tekst (context) een gecontextualiseerde versie.
Deze informele weergave van het mechanisme komt goeddeels overeen met het schema Scaled Dot-product Attention:
- De berekening van het inproduct is de onderste MatMul (matrix-vermenigvuldiging) in het schema. Meestal gebruiken wij als notatie voor het inproduct
 . Dot product immers. Wiskundig gezien is het inzichtelijker om het als matrix vermenigvuldiging te schrijven:
. Dot product immers. Wiskundig gezien is het inzichtelijker om het als matrix vermenigvuldiging te schrijven:  .
. - In het blok Normaliseren zijn de bewerkingen Scale en Softmax uit het schema gecombineerd.
- Bij het schalen worden alle inproduct-waarden vermenigvuldig met
 waarbij d de lengtedimensie van de vectoren is. Zo worden de scores, d.i. de waarden van de inproducten, niet al te groot.
waarbij d de lengtedimensie van de vectoren is. Zo worden de scores, d.i. de waarden van de inproducten, niet al te groot. - De Softmax functie zorgt er voor dat de gewichten uiteindelijk allemaal getallen tussen 0 en 1 zijn, zodanig dat per vector de som van de gewichten gelijk aan 1 is.
- Bij het schalen worden alle inproduct-waarden vermenigvuldig met
- De berekening van de gecontextualiseerde vectoren
 in ons plaatje is de bovenste MatMul in het schema.
in ons plaatje is de bovenste MatMul in het schema. - In het schema staat nog de optionele Mask. Deze wordt gebruikt bij ‘gatentekst’-achtige taken (zoals bij seq2seq vertalingen).
Contextvectoren door gewichten
De uitkomst van het attention mechanisme zijn de vectoren die we in het plaatje aanduiden met , de gecontextualiseerde versies van  , kortweg de contextvectoren. Uitgeschreven ziet dat er zo uit:
, kortweg de contextvectoren. Uitgeschreven ziet dat er zo uit:



De genoemde  en
en  zijn scalairen, dimensieloze getallen, die de rol van gewichten vervullen zoals we die eerder hebben gezien bij machine learning. De context wordt gevormd door de woorden (tokens) die we aan het systeem meegeven. Die woorden hebben in het taalmodel een embedding in de vorm van woordvectoren met een groot aantal eigenschappen uit de (pre-)training van het model.
zijn scalairen, dimensieloze getallen, die de rol van gewichten vervullen zoals we die eerder hebben gezien bij machine learning. De context wordt gevormd door de woorden (tokens) die we aan het systeem meegeven. Die woorden hebben in het taalmodel een embedding in de vorm van woordvectoren met een groot aantal eigenschappen uit de (pre-)training van het model.
Query, Key en Value
Wat doet het attention mechanisme? Naïef geformuleerd zit het volgens mij ongeveer zo: een woord, vertegenwoordigd door zijn vector, “vraagt” als het ware aan het mechanisme om te vertellen welke invloed de verschillende woorden in de context hebben op de betekenis van dat woord. Zo’n woord uit de context, ook vertegenwoordigd door zijn vector, is dan de “sleutel” tot de invloed van dat woord op de betekenis. De “waarde” die uit de berekeningen komt vormt het antwoord dat andermaal een woordvector is. Die berekeningen bestaan uit inproducten en uitkomsten van normalisatie.
Nu hebben we de goede woorden te pakken. Lees voor vraag Query, voor sleutel Key en voor waarde Value en kijk nog eens naar het schema uit het artikel: je ziet onderaan Q en K de eerste matrixvermenigvuldiging MatMul in gaan (dat is het inproduct) en V de tweede MatMul (dat is het verrekenen van de gewichten). Het schema is de formele vertaling van mijn naïeve weergave.
Een gedachte om even vast te houden. Q, K en V worden vertegenwoordigd door vectoren, Q en K op voorhand zelfs door het zelfde stel . Als de woorden in de context géén invloed op elkaar hebben, of we hebben die nog niet kunnen vaststellen, dan zijn de gewichten natuurlijk gelijk aan 0, behálve het gewicht  van het woord op zichzelf – dat is dan gelijk aan 1. Als je de waarden invult in de uitgeschreven uitkomst hierboven dan zie je dat
van het woord op zichzelf – dat is dan gelijk aan 1. Als je de waarden invult in de uitgeschreven uitkomst hierboven dan zie je dat  (de andere termen vallen weg).
(de andere termen vallen weg).
In de beginsituatie zijn Q, K en V aan elkaar gelijk.
Matrices
Waar komen nu die matrices te tevoorschijn? Als je het hele verhaal terugleest dan zie je dat er weliswaar iets uitkomt dat we gewichten noemen, maar dat het gedetermineerde, onveranderlijke, waarden zijn gegeven de context en de getrainde inhoud van het taalmodel. Er kan nog niets ‘geleerd’ worden.
Dat wordt in de Transformer architectuur opgelost door de vectoren in te bedden in matrices met veranderbare gewichten die op basis van feed forward en backward propagation aangepast, aangeleerd, kunnen worden door het model. En daar waar we in de startsituatie alleen de vectoren hebben, maken we drie verschillende gewichten-matrices: een voor Q, een voor K en een voor V.
De laatste stap: next token prediction
We hebben nog niet alle onderdelen van de architectuur besproken, met name het samenspel tussen de encoder en de decoder vraagt nog (veel) uitleg, maar ik wil dit bericht eindigen met de laatste componenten van de architectuur. Met laatste bedoel ik de uiteindelijke voorspelling van een volgend woord (als het om een talige context gaat).
Het totale schema uit het oorspronkelijke artikel zie je hier, de encoder in het linkerdeel, de decoder staat rechts. Merk op dat er bij beide “Nx” naast staat, dat wil zeggen dat eenzelfde onderdeel N maal herhaald wordt, afhankelijk van de complexiteit van de situatie.
Helemaal rechtsboven zie je de uitvoer staan, Output Probabilities. Die wordt geproduceerd door een Softmax component en een Linear component die worden toegepast op de output die de decoder verlaat.
De Linear laag is een volledig verbonden neuraal netwerk (een zg. dense neural network) die de contextvectoren die uit de decoder komen omzet in een veel grotere vector, de zg logits vector. Deze vector bevat de waarschijnlijkheden van alle mogelijke uitkomsten die het taalmodel kent en kan verbinden aan de contextvectoren.
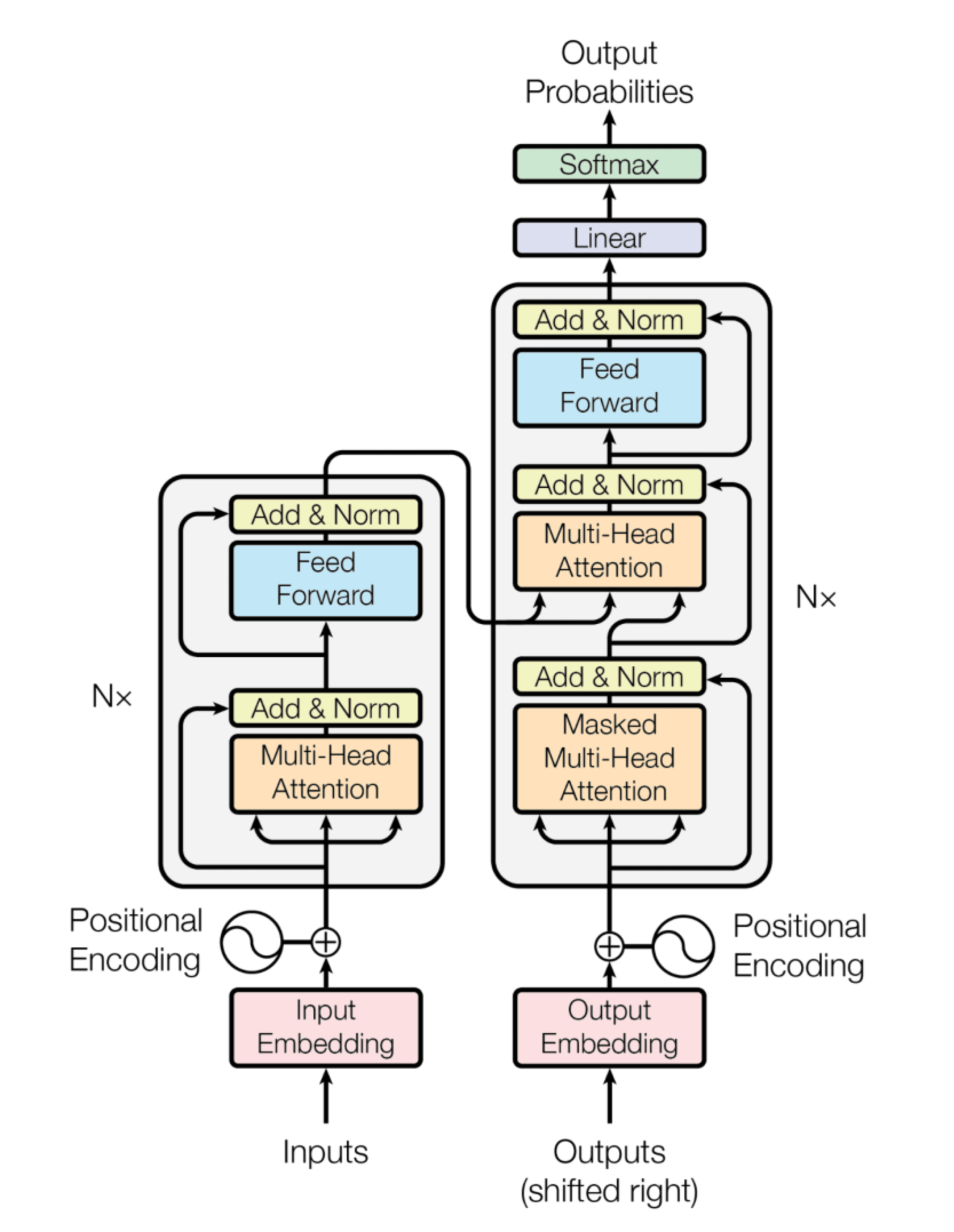
De Softmax laag maakt van alle scores in de logits vector een keurig genormaliseerde kansverdeling (i.e. waarden tussen 0 en 1, bij elkaar opgeteld gelijk aan 1). De hoogste waarde in die verdeling geeft de voorspelling voor het meest plausibele volgende woord.