
De T van GPT
Natuurlijk ben ik niet de enige die het belang van de Transformer model architectuur voor de ontwikkeling van AI hoog inschat.
Je vindt daarom op internet een overvloed aan presentaties en video’s met uitleg van de architectuur. Het ligt misschien aan mijn nieuwigheid op dit terrein, maar een aantal ervan kan ik niet goed volgen, ik raak de draad kwijt of snap de strekking van het verhaal niet.
En veel andere gaan niet diep genoeg of praten andere na. Zó belangrijk, die multi-head attention… maar ik blijf zitten met vragen. Waarom dan? En hoe?
Ik was van plan om hier een gedetailleerde uitleg van het oorspronkelijke artikel te geven, voor mij de snelste manier om de materie zelf te leren begrijpen. Bij nader inzien kies ik voor een splitsing in de uitwerking. In dit bericht staan de conceptuele hoofdlijnen, in een later bericht komen de technische en wiskundige details.
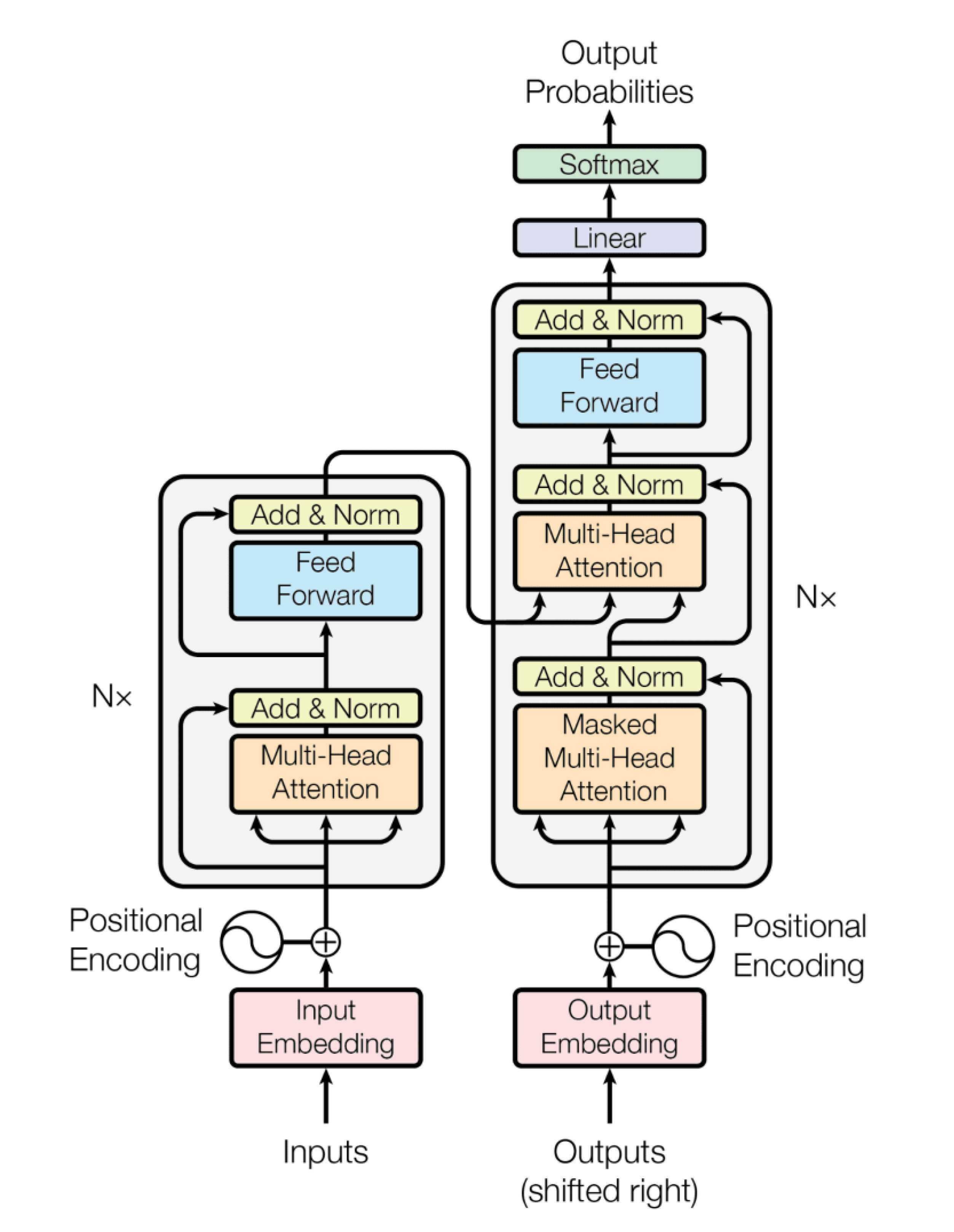
Waar waren we ook al weer?
- We zijn in de wereld van deep learning, natuurlijke taalverwerking en de grote taalmodellen.
- Die modellen ondergaan een pre-training op een tekstcorpus van onvoorstelbaar grote omvang en variëteit en zijn daarna in staat om gebruikersinvoer in natuurlijke taal te interpreteren en er op te reageren, output te geven, ook in natuurlijke taal.
- Die output wordt letterlijk woord voor woord gemaakt door na elk ‘afgeleverd’ woord vast te stellen welk woord nu het meest plausibel is voor het vervolg.
- De mate van plausibiliteit wordt bepaald door de input van de gebruiker, de context die daardoor wordt opgeroepen en de ‘ervaring’ van het getrainde systeem. En marge wil ik hier opmerken dat ‘plausibiliteit’ niets zegt over ‘waarheid’ of ‘correctheid’.
- De computers waarop deze modellen worden uitgevoerd doen sequence-to-sequence taken. De invoer bestaat uit sequenties van woorden en ook de uitvoer bestaat weer uit zulke sequenties.
- Een computer kan alleen met getallen werken. De talige invoer wordt omgezet in reeksen getallen. Daarmee worden berekeningen uitgevoerd die leiden tot nieuwe reeksen getallen. Die worden daarna zelf weer omgezet naar woorden en zinnen. Zie hier voor een overzicht van het benodigde voorwerk.
- Taal is weerbarstig als het om betekenis gaat. Volgorde van woorden doet er toe voor de betekenis van zowel individuele woorden als de hele tekst, net als het voorkomen van een combinatie van woord met andere woorden. Niet elk woord in een sequentie is van even groot belang voor de betekenis van de hele zin of tekst.
Architectuur
- Van belang is dat de neurale netwerken die taalmodellen moeten uitvoeren zodanig zijn ingericht dat zowel volgorde als plaats van een woord in een tekst kan worden herkend, opgeslagen en gebruikt bij de verdere verwerking. Zoals men zegt: die netwerken moeten voor dit doel een geschikte architectuur hebben.
- Alle sequence-to-sequence taken kunnen in principe uitgevoerd worden met neurale netwerken die een recurrente architectuur hebben, met vele hidden layers, maar in de praktijk lukt dat niet bij meer omvangrijke tekstuele input. Eerlijk gezegd wordt de grens al vrij snel bereikt omdat het aantal benodigde layers (en daarmee het benodigde computergeheugen) kwadratisch toeneemt. In de praktische uitvoering worden daarom niet alle benodigde lagen ingezet, met inhoudelijke gevolgen.
- Recurrente architecturen hebben minstens twee nadelen.
- Bij de uitvoering van de taken moeten woorden steeds een voor een worden verwerkt. Bij grotere teksten is de trage verwerking die hier het gevolg van is een onoverkomelijk probleem.
- Als een woord dat van essentieel belang is voor de betekenis van een tekst ‘te ver’ vooraan staat is het model dat woord al weer ‘vergeten’ vanwege de beperking in benodigde hidden layers.
- De Transformer architectuur van een deep learning model wordt als een doorbraak gezien.
- Door het gebruik van aandachtsmechanismen, zoals self attention, wint het vaststellen van betekenisverwantschap sterk aan kwaliteit. Binnen een context wordt een woord in relatie gebracht met alle andere woorden van die context. Per woordcombinatie wordt een gewicht bepaald. Van de context worden geen woorden vergeten of weggeschoven.
- De gewichten zijn ‘leerbaar’, dat is de essentie van deep learning modellen. Aan de hand van een zogenoemde ‘loss function‘, een rapportcijfer voor het verschil tussen huidig en gewenst resultaat, worden de gewichten ingeregeld totdat een optimaal resultaat ontstaat. Feed forward en backward propagation zijn hier de jargon woorden die aangeven dat het een ‘heen-en-weer’-proces is.
- Zo opgeschreven wordt niet alleen de output woord voor woord bepaald, maar worden de woorden in de context die er toe doen ook een-voor-een ingeregeld. De Transformer architectuur maakt een parallelle afhandeling mogelijk, dat is wat in het plaatje Multi-Head Attention wordt genoemd.
- Aan het einde van een deep learning cyclus worden de gewogen uitkomsten onderling vergeleken. Op basis daarvan wordt het meest plausibele volgende woord bepaald. In het jargon: next-token prediction.
Wiskunde
De wiskunde die er bij te pas komt bestaat vooral uit het rekenen met vectoren, in het bijzonder met het inproduct van vectoren, dot product in het Engels (ook wel scalair product). De vectoren zijn woordvectoren waarin een groot aantal eigenschappen, features, getalsmatig is vastgelegd. Het inproduct van twee vectoren is één enkel getal, dat een maat vormt voor de mate van verwantschap in de betekeniseigenschappen.
Bij één woord hoort één vector. De woorden uit een zin, of nog ruimere context, hebben een verzameling vectoren die je in de vorm van een matrix kunt opschrijven. Matrixrekening is de wiskundige discipline die hier van pas komt en die je in staat stelt de berekeningen voor de tekst die onderhanden is in één greep zichtbaar te maken.
Naast alle matrixberekeningen zijn er nog wiskundige functies nodig om uiteenlopende teksten vergelijkbaar te maken: normalisatie. Tot slot wordt aan de hand van de scores bepaald welk woord, welk token, wordt voorgedragen voor ‘meest plausibel’. Hiervoor wordt de Softmax-functie gebruikt die je ook in de afbeelding genoemd ziet staan.
Het oorspronkelijke artikel over de Transformer architectuur stelt allereerst structuur en bewerkingsstrategie vast, en doet daarbij een suggestie voor het wiskundig instrumentarium dat je zou kunnen gebruiken. Zoals ik het nu zie is het wiskundig instrumentarium precies wat het zegt: een verzameling hulpmiddelen om verbanden te beschrijven en vast te leggen, met aspecten van normeren en optimaliseren er in. Er is niet nog een semantische, ‘diepere’, betekenis van de gebruikte wiskunde.
In een volgend bericht wil ik aan de hand van een voorbeeld de structuur en de stappen doorlopen. Zo kan ik ook testen of mijn inschatting van de aard van de benodigde wiskunde (= instrumentarium) terecht is.