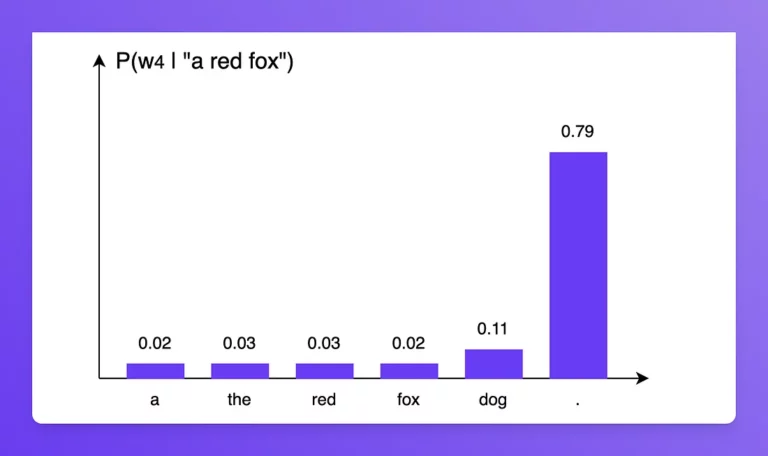
Héél grote dataverzamelingen
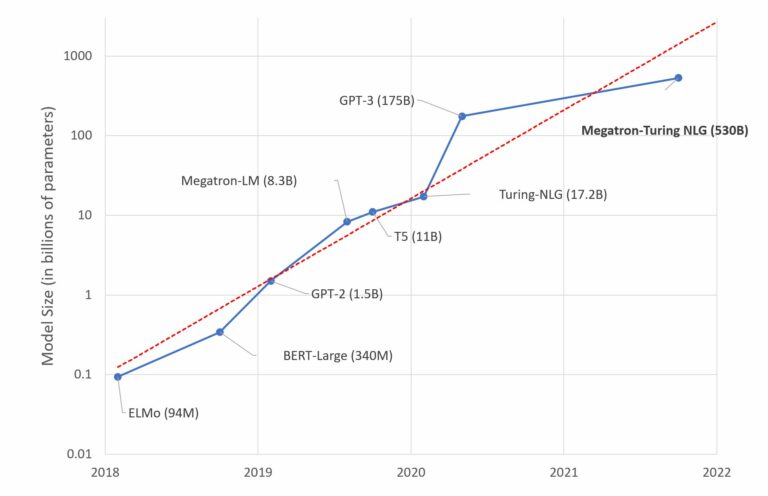
Taalmodellen zoals GPT-3 worden gereedgemaakt voor gebruik door ze te ‘trainen’ op grote dataverzamelingen. Ik denk al wel te begrijpen dat de onvoorstelbare omvang van het corpus waarop GPT-3 is getraind een van de kantelpunten markeert waarnaar ik op zoek…